
After quite a few months of writing and polishing, my PhD thesis is now available on the e-print repository of my university. And a few weeks ago, I have successfully defended the thesis in an oral examination:
Congratulations to @j_vamvas , who just passed his viva on "Model-based Evaluation of Multilinguality"! With thanks to the examiners @unattributed and @LenaAJaeger . pic.twitter.com/vhwp8CtTWy
— Zurich Computational Linguistics Group (@cl_uzh) March 13, 2023
My thesis combines four research papers published in 2021 and 2022. All the papers were co-authored with my main supervisor, Rico Sennrich. Earlier, I have summarized the papers on this blog: 1, 2a and 2b, 3, and 4.
What I added to the thesis was a 40-page introduction with some additional context. The introduction characterizes the key problem: how to evaluate modern natural language processing (NLP) systems in multiple languages. Many of these systems – like GPT, DeepL or Google Translate – are designed to handle multilingual input. Evaluation means figuring out how well the systems do in comparison to each other and to humans.
Good evaluation practice is necessary for multiple reasons: for research and development (doing experiments and measuring the effect of changes), for real-world applications (ensuring safety) and for society at large (understanding when NLP systems are working well and when they are failing). But multilinguality remains a great challenge, mostly because there are so many languages in the world, but also because resources, including human resources, are not equally available for all languages.
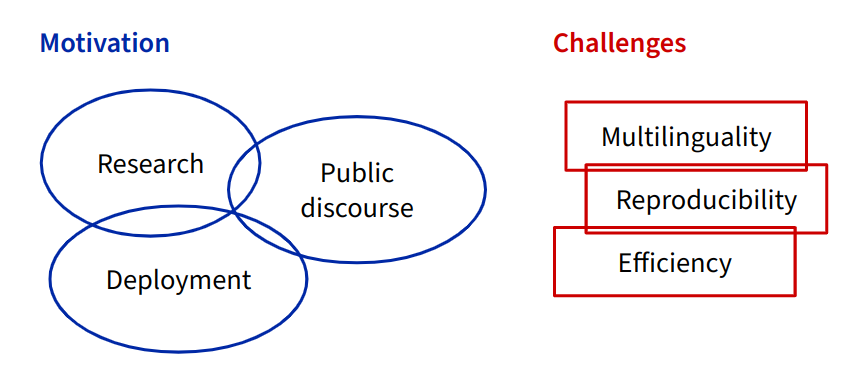
Most contributions in the thesis focus on targeted evaluation, where a specific aspect of system quality is examined. There is a lot of previous work on targeted evaluation; for example, the WinoMT challenge (Stanovsky et al., 2019) specifically looked into occupation nouns like ‘doctor’ and their translation in terms of gender. Current machine translation (MT) systems have an overgeneralization bias and tend to resort to whatever has been the majority gender in the training data, often ignoring the gender information in the input sentence:
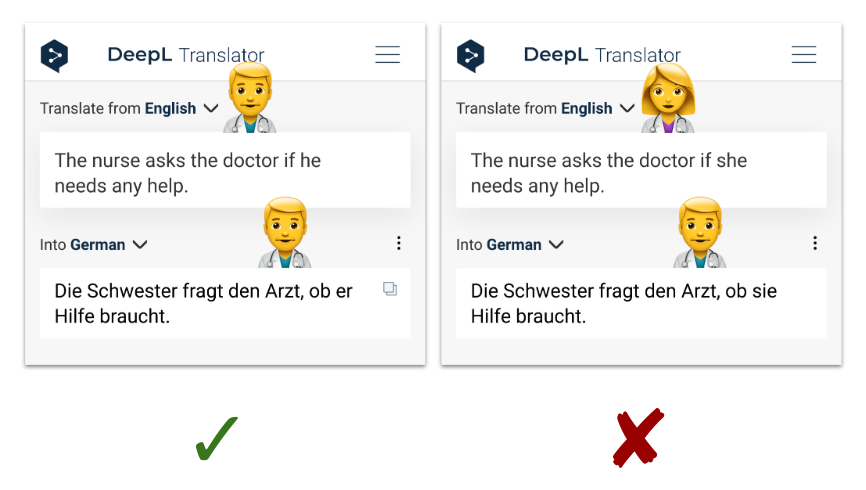 An English–German example for WinoMT. I have annotated the gender of ‘doctor’ and its translations with emoji. Note that this is not a shortcoming of DeepL in particular – other MT systems tend to do similarly bad.
An English–German example for WinoMT. I have annotated the gender of ‘doctor’ and its translations with emoji. Note that this is not a shortcoming of DeepL in particular – other MT systems tend to do similarly bad.
But the idea behind WinoMT poses a challenge to evaluation as well: How can we account for the fact that there are many good translations of these sentences, and still reliably judge whether the occupation noun has been correctly translated in terms of gender? My thesis discusses different methods for targeted evaluation and presents novel experiments that highlight limitations in previous methods (Vamvas and Sennrich, 2021). We then propose a new model-based targeted evaluation method called Contrastive Conditioning.
The idea behind Contrastive Conditioning is to classify the machine translation using another MT system. We can delegate the evaluation process to that system if we provide it with extra information via an augmented source sequence:
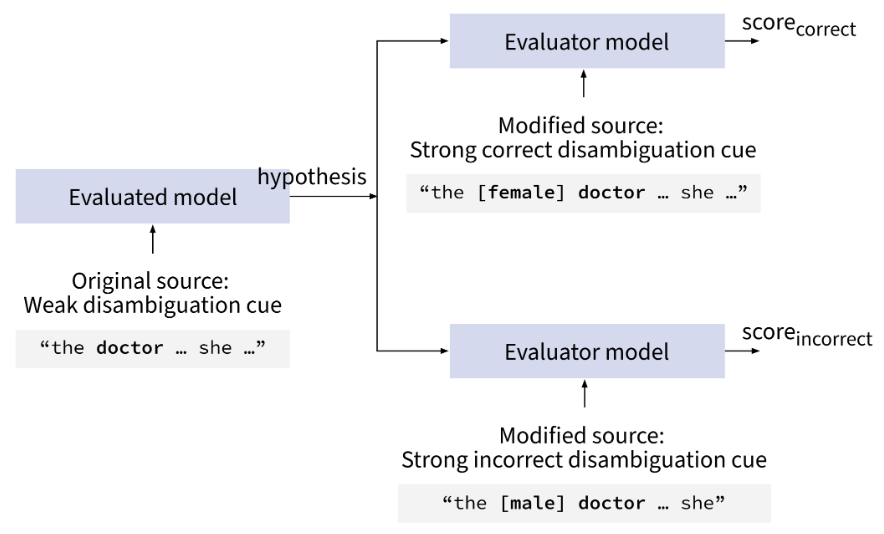
Model-based evaluation allows us to scale the evaluation across multiple target languages, without having to create custom test sets for every target language. Another advantage of our method is that anyone can automatically analyze the translations from black-box systems like DeepL. Our method does not require access to the system that has generated the machine translations.
In the thesis, we demonstrate how the method can be applied to the problems of (1) measuring lexical overgeneralization bias in MT (like WinoMT) and showing that distilled translation models overgeneralize more strongly (Vamvas and Sennrich, 2021), and (2) detecting coverage errors in MT, e.g., detecting whether information has been lost in translation (Vamvas and Sennrich, 2022).
A recurring idea in the thesis is that MT systems can be useful beyond translation: as a model of multilinguality and of semantic equivalence across languages. A perfect example is the method described above, since Contrastive Conditioning makes use of MT to automate targeted evaluation. But in our last paper, we looked at the idea from a different angle and demonstrated different ways of how an MT system can be queried for estimating semantic similarity (Vamvas and Sennrich, 2022).
Specifically, MT systems can judge whether two sentences are paraphrases of each other (Thompson and Post, 2020). This is especially interesting if phrases seem to look similar but have an opposite meaning, as in “Flights from New York to Florida” vs. “Flights from Florida to New York”. In that case, we showed that MT-based approaches, such as our proposed translation cross-likelihood measure, are much more accurate than alternative approaches:
 Accuracy of different text similarity measures on paraphrase identification (on average across test sets in 9 languages).
The accuracy of translation-based measures can be increased by applying a normalization (dark red), such as reconstruction normalization.
Accuracy of different text similarity measures on paraphrase identification (on average across test sets in 9 languages).
The accuracy of translation-based measures can be increased by applying a normalization (dark red), such as reconstruction normalization.
Overall, I see my thesis as a contribution towards extending the range of technical possibilities in multilingual NLP evaluation. But there are still many limitations, including fundamental ones. Seventy years ago, Warren Weaver (1894–1978), an influential technologist at the dawn of the computer age, put forward four principles that he saw as crucial for advancing NLP (Weaver, 1952). In the introduction to my thesis, I revisit his memorandum and find that three of his principles have been realized by now, in some form or other. The principles envisioned by Weaver – contextualization, machine learning and information theory – are now closely reflected in the state of the art of NLP.
However, his memorandum concludes with a fourth principle: multilinguality. And while this idea has inspired research ever since, the terms in which modern NLP systems can be understood as being truly multilingual are still unclear. Common to the methods presented in this thesis is a functionalist approach – crafting inputs and observing the outputs of NLP systems. To bring Weaver’s Fourth Principle to fruition and to verify its success, a functionalist approach might not be enough for NLP.
The work presented in this post was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727). I thank the members of the supervisory and doctoral committees for their valuable feedback.
References
Gabriel Stanovsky, Noah A. Smith, and Luke Zettlemoyer. Evaluating gender bias in machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 1679–1684. Florence, Italy, July 2019. Association for Computational Linguistics. URL: https://aclanthology.org/P19-1164, doi:10.18653/v1/P19-1164. ↩
Brian Thompson and Matt Post. Automatic machine translation evaluation in many languages via zero-shot paraphrasing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 90–121. Online, November 2020. Association for Computational Linguistics. URL: https://aclanthology.org/2020.emnlp-main.8, doi:10.18653/v1/2020.emnlp-main.8. ↩
Jannis Vamvas and Rico Sennrich. Contrastive conditioning for assessing disambiguation in MT: A case study of distilled bias. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 10246–10265. Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. URL: https://aclanthology.org/2021.emnlp-main.803, doi:10.18653/v1/2021.emnlp-main.803. ↩
Jannis Vamvas and Rico Sennrich. On the limits of minimal pairs in contrastive evaluation. In Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, 58–68. Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. URL: https://aclanthology.org/2021.blackboxnlp-1.5, doi:10.18653/v1/2021.blackboxnlp-1.5. ↩
Jannis Vamvas and Rico Sennrich. As little as possible, as much as necessary: detecting over- and undertranslations with contrastive conditioning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 490–500. Dublin, Ireland, May 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.acl-short.53. ↩
Jannis Vamvas and Rico Sennrich. NMTScore: a multilingual analysis of translation-based text similarity measures. In Findings of the Association for Computational Linguistics: EMNLP 2022, 198–213. Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.findings-emnlp.15. ↩
Warren Weaver. Translation. In Proceedings of the Conference on Mechanical Translation. Massachusetts Institute of Technology, 17-20 June 1952. URL: https://aclanthology.org/1952.earlymt-1.1. ↩