
In a paper presented at EMNLP 2021, we propose a new technique for evaluating disambiguation in machine translation called contrastive conditioning. This post is an introduction to the core ideas behind the technique.
White-Box vs. Black-Box MT
Machine translation (MT) comes with different user interfaces. Systems created in a research lab are white-box systems, which means that the code and the model weights are available to the researchers. On the other hand, commercial MT systems such as Google Translate are black boxes to most users. Independent researchers can only observe what goes in (the source sentence) and what comes out (the machine translation).
As MT systems are getting better and better, targeted evaluation has become more important. MT researchers analyze the performance of systems regarding specific linguistic phenomena, using carefully crafted test data. Scaling such a targeted evaluation is easier if you can peek into the model internals.
Contrastive Evaluation
A perfect example is the contrastive evaluation technique (Sennrich, 2017). There, the idea is to suggest two different translation variants to the model. The first variant is a correct translation and the second one contains the error type you're interested in:
 Example for contrastive evaluation of an MT system (English–German). In this post, I am using the error type "wrong disambiguation of Turkey" as an example, since when translating from English into German, you need to choose between Türkei (the country) and Truthahn (the bird). This is just an illustrating example, not an error that a modern MT system is likely to make.
Example for contrastive evaluation of an MT system (English–German). In this post, I am using the error type "wrong disambiguation of Turkey" as an example, since when translating from English into German, you need to choose between Türkei (the country) and Truthahn (the bird). This is just an illustrating example, not an error that a modern MT system is likely to make.
One can expect that a good model assigns a higher score to the correct translation, like in the example above. However, such scores (probability estimates of a translation given a source sentence) can only be computed with white-box systems. You cannot apply contrastive evaluation to Google Translate and similar services.
Pattern-Matching Evaluation
To also subject black-box MT to targeted evaluation, researchers have come up with pattern-matching approaches that automatically analyze the translation output. For example, Raganato et al. (2020) search the translation for different BabelNet senses, which in our example allows them to check whether Turkey is translated correctly into German:
 Example for a pattern-matching evaluation (English–German)
Example for a pattern-matching evaluation (English–German)
However, there are always going to be a few translations (let's say 20%) that do not match any of the patterns. Natural language has many ways of expressing a concept, and it is difficult to enumerate them all. Another drawback, which also applies to contrastive evaluation, is that you need to prepare data for every target language of interest.
What we find exciting about the new method is that it promises, at least for phenomena such as lexical disambiguation, to combine the best of both worlds: The recall of contrastive evaluation and the black-box accessibility of pattern-matching.
Inspiration for Contrastive Conditioning
The basic idea is that by varying the source sequence to provide more disambiguation cues, you can learn about the ground truth without speaking the target language. For example, let's begin with our original, slightly ambiguous Turkey sentence:
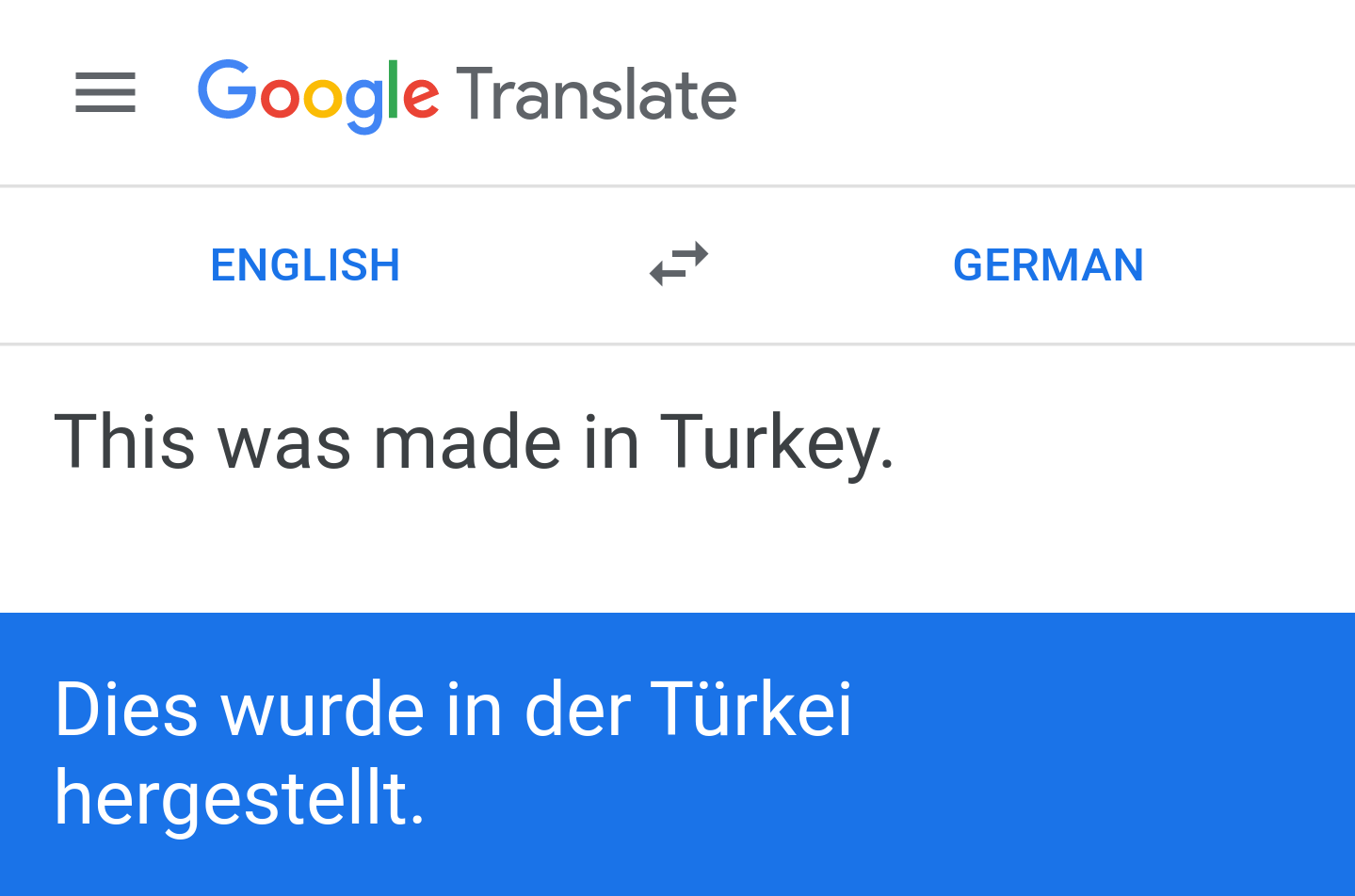
If you replace Turkey with modern Turkey, you give Google Translate an additional cue that Turkey is supposed to be a country, not a bird. Given such a cue, Google Translate is less likely to make a disambiguation error:

Since Google Translate has not stopped using the German word Türkei, the original sentence seems to have been translated correctly. You can verify this by replacing modern Turkey with frozen Turkey:
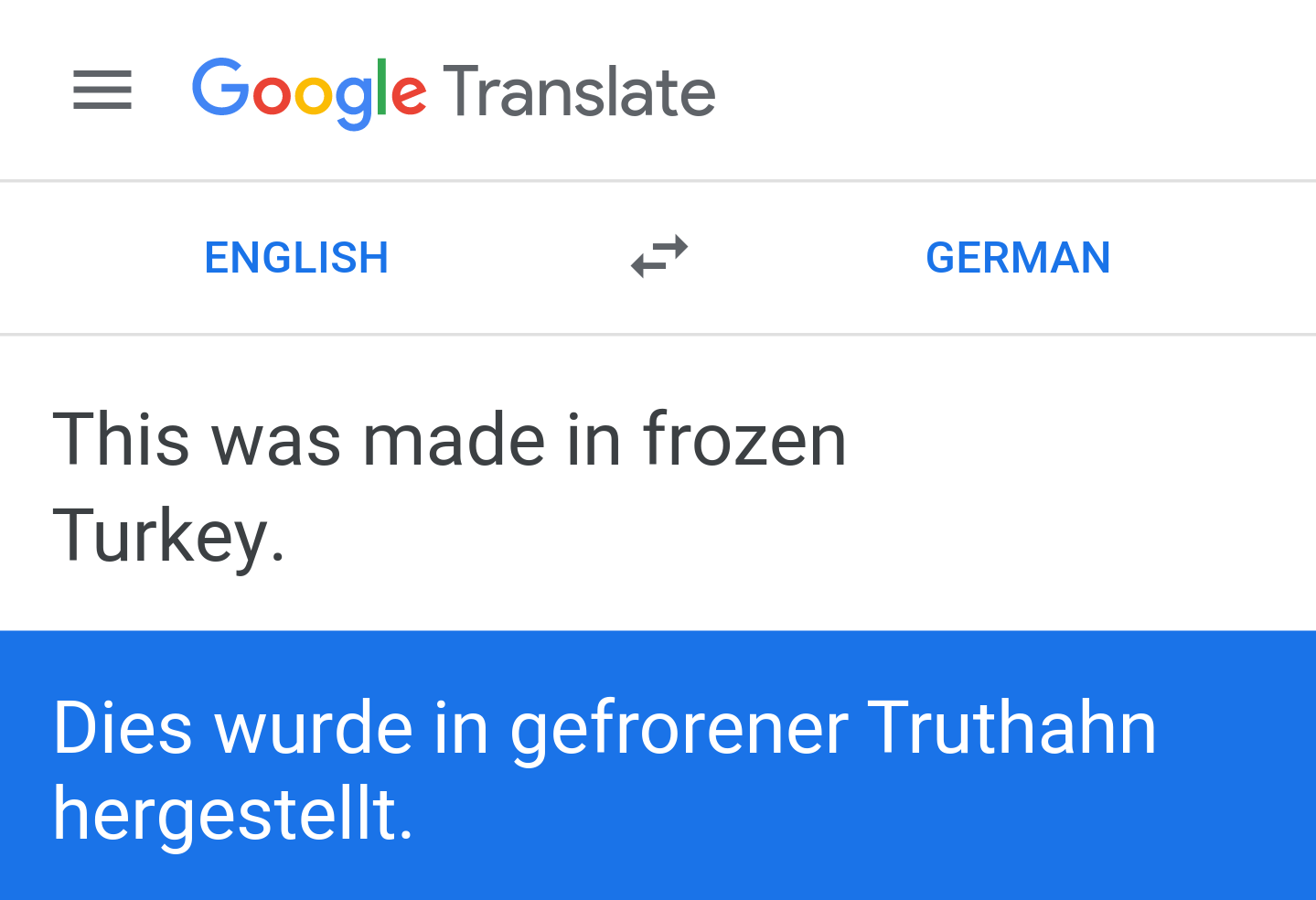
The word Türkei has now disappeared from the translation, which is further proof that Türkei refers to a country, and not to a bird.
Formalization
Countless power users of MT have probably already come up with this algorithm. The challenge is to apply it to targeted evaluation in a systematic and formalized way.
Our approach is based on scoring, like in contrastive evaluation. However, what we score is not a human-crafted translation, but the translation by the MT system. We compute two scores for the translation: one score based on a correct disambiguation cue, and another score based on an incorrect disambiguation cue. If the first score is higher than the second score, the translation is probably correct:
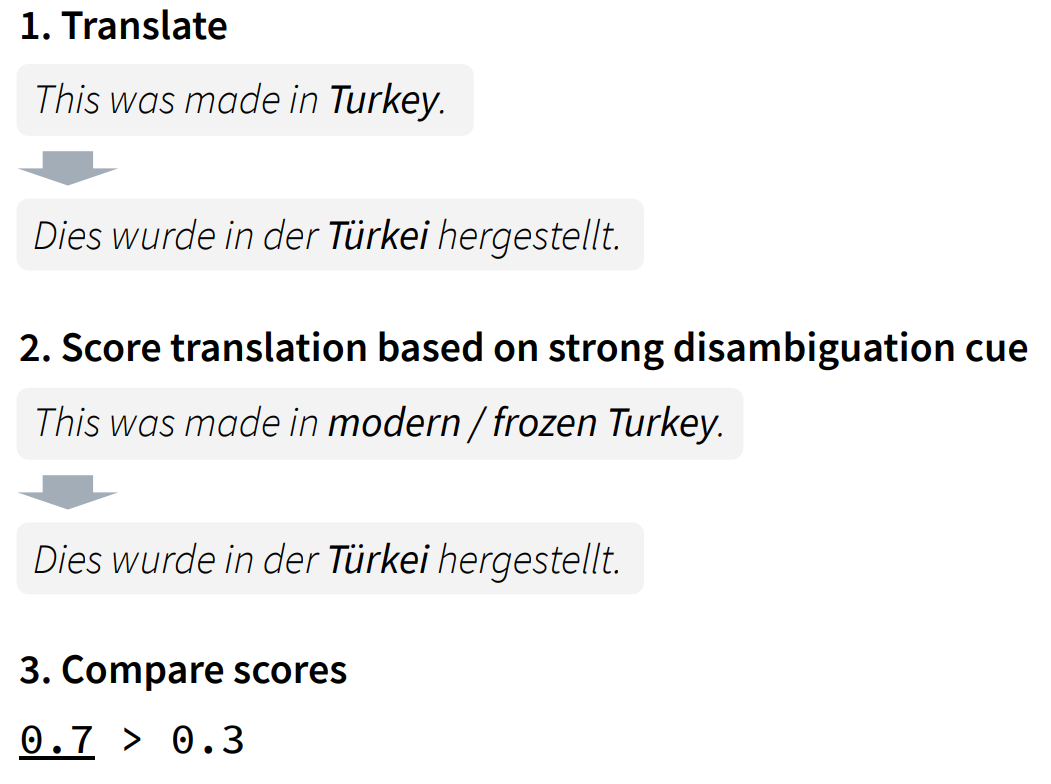
To make things more clear, let's do a comparison to the standard approach of contrastive evaluation: In the standard approach, two contrastive variants of the translation are scored, conditioned on the same source sequence. In our approach (contrastive conditioning), the same translation is scored twice, conditioned on contrastive variants on the source.
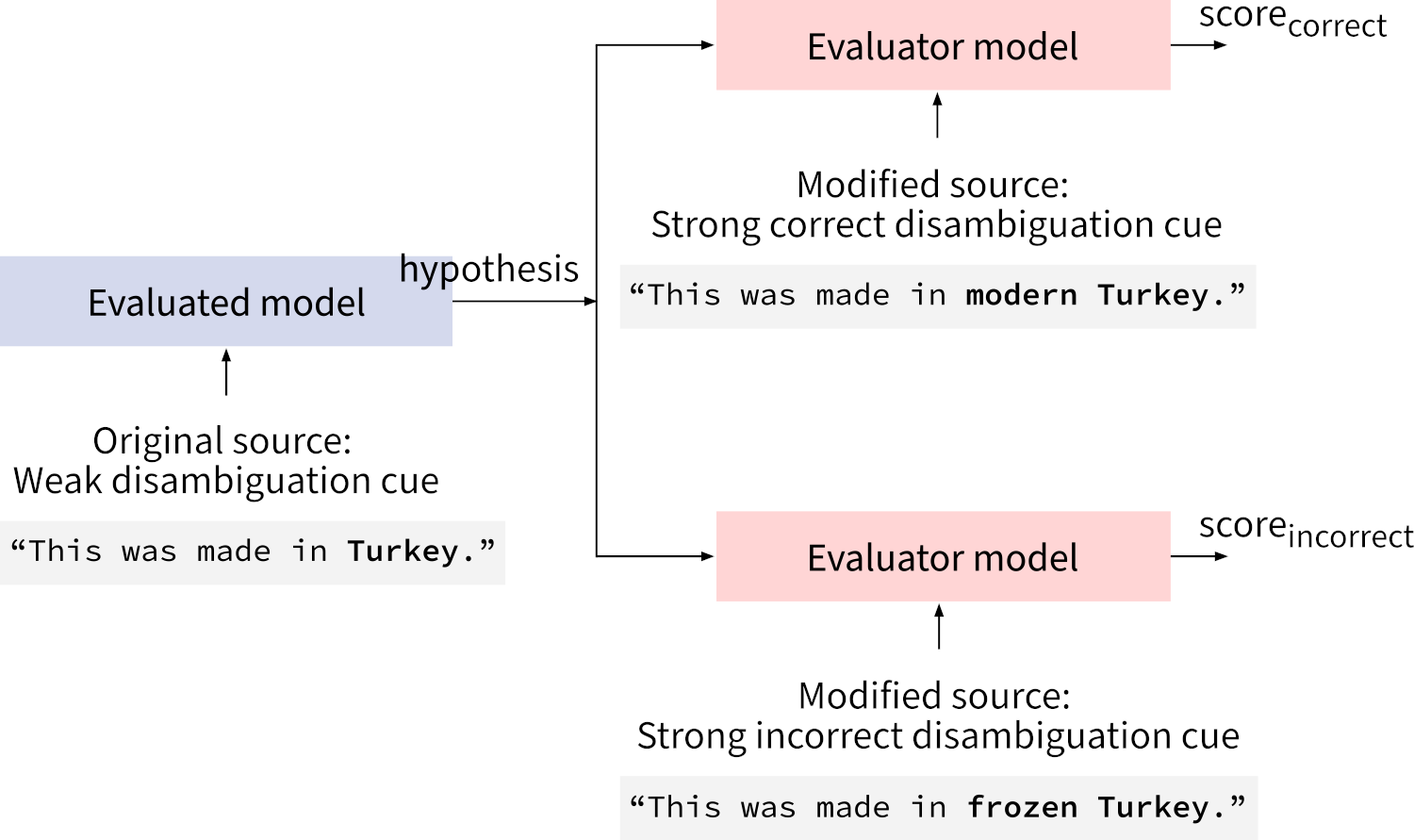
That may not seem like a big difference. But crucially, our method does not depend on the evaluated model to produce the scores. It only requires a translation output, and then any MT system can play the role of an evaluator model. If you are evaluating a black box you need an additional white-box MT system for that (for example from the OPUS-MT project).
Other Benefits
In addition to its black-box nature, contrastive conditioning has a few other interesting properties. For example, since the ratio between the two scores can be seen as the confidence of the evaluator, it is possible to weigh the test samples by this confidence. This is helpful if some test samples are difficult to judge.
Another advantage is that the test data can be reference-free. All the contrastive modifications happen in the source language. In that sense, contrastive conditioning is easy to scale across many target languages.
Outlook
It is an open question how many linguistic phenomena are amenable to contrastive conditioning. In our paper, we perform a successful case study on two well-known challenges for MT: Word sense disambiguation and the translation of gendered occupation names into morphologically rich languages. I am going to discuss our findings in a follow-up post.
It will be interesting to see whether phenomena beyond disambiguation can also be evaluated using contrastive conditioning. And in my view, disambiguation remains a great challenge for MT, even though few modern systems are as bad as the one that produced that infamous clothing label:
🤷♂️ German is hard... pic.twitter.com/Qe81wLhAnQ
— Benedikt Meurer (@bmeurer) March 19, 2019
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Alessandro Raganato, Yves Scherrer, and Jörg Tiedemann. An evaluation benchmark for testing the word sense disambiguation capabilities of machine translation systems. In Proceedings of the 12th Language Resources and Evaluation Conference, 3668–3675. Marseille, France, May 2020. European Language Resources Association. URL: https://www.aclweb.org/anthology/2020.lrec-1.452. ↩
Rico Sennrich. How grammatical is character-level neural machine translation? assessing MT quality with contrastive translation pairs. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 376–382. Valencia, Spain, April 2017. Association for Computational Linguistics. URL: https://www.aclweb.org/anthology/E17-2060. ↩