
In a paper presented at EMNLP 2021, we take a closer look at lexical overgeneralization in MT. The first part of the paper introduces a new technique for evaluating disambiguation, called contrastive conditioning (→ blog post). Here's an introduction to the second part of our paper: A case study showing that distilled MT models have a stronger overgeneralization bias.
The Impact of Disambiguation Errors
One of the great challenges of machine translation (MT) is inferring the correct word sense of ambiguous words. There are different ways in which words can be ambiguous – a well-known example are nouns that can mean multiple things.
For instance, the English noun starter can refer to an appetizer or to a motor part.
Since German has different words for the two concepts, an MT system needs to decide between Vorspeise and Anlasser when translating starter into German:

Context usually helps with disambiguation. A starter that is made of avocados is probably not a motor part. But MT systems sometimes ignore this context and make disambiguation errors in spite of it.
Another interesting example are gendered occupation names. Stanovsky et al. (2019) have demonstrated how even the best MT systems tend to ignore pronouns when translating occupation names from English. This is a problem because morphologically rich languages such as German have different forms for female and male occupation holders:

What is especially unpleasant about such errors is that they are systematic: MT systems tend to ignore female pronouns more often than male pronouns. This is because the training data contain many more male occupation names, among other factors. Thus, disambiguation errors in MT are mostly caused by an overgeneralization of the training data.
Clearly, overgeneralization hurts the adequacy of machine translations. But when it comes to overgeneralization of gender, many people see an ethical problem as well. For example, if you are concerned about the dominance of male forms in human-written German texts (as many feminist linguists are), then you should also be concerned about an even greater dominance of male forms in the output of MT systems.
Background: Distillation for MT
In our case study we look at a technique called sequence-level knowledge distillation, since there are reasons to believe that it increases overgeneralization. This technique, originally proposed by Kim and Rush (2016), is often used to reduce the size of an MT model, for example to make it fit on your phone.
The idea is to use not one but three steps to train the model:
- Train a normal MT model ("teacher").
- Re-translate all the training data with the teacher.
- Train a smaller MT model ("student") on those data.
A student model trained like this usually reaches a better BLEU score than if it had been trained on the original data. This means that there must be a difference between the original and the distilled data that makes training a model easier. While many researchers have looked for such a difference, this figure derived from a paper by Zhou et al. (2020) is a good visualization:
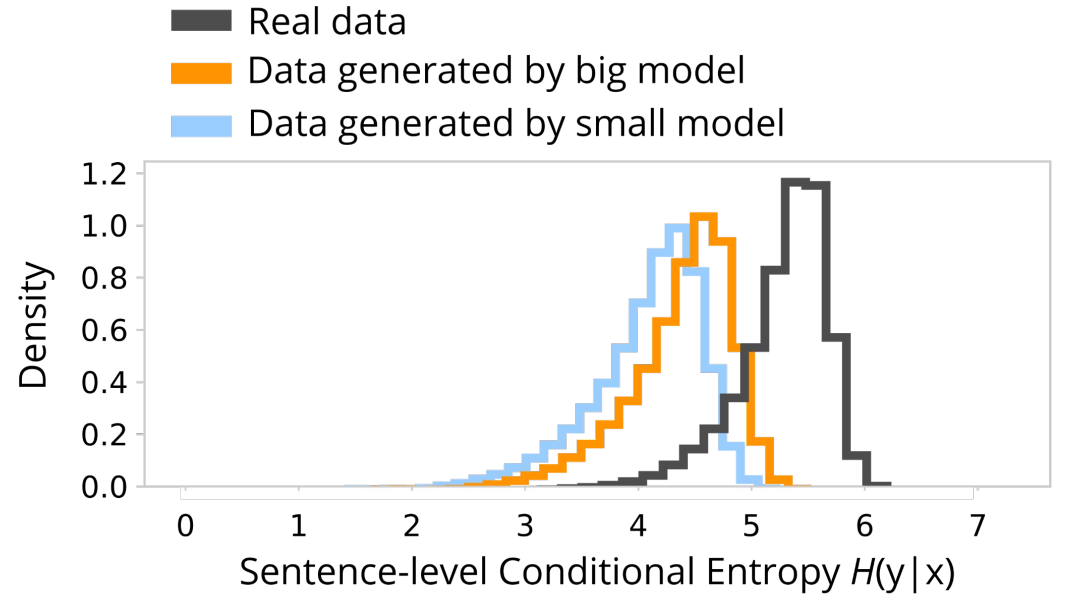
The distilled translations are more predictable given the source sentences. This means that they follow the structure of the source more closely and contain less human noise.
Our hypothesis was that the same phenomenon also leads student models to commit more disambiguation errors due to overgeneralization.
Distillation leads to Overgeneralization
A very simple test method is to count the words in the different strata of the training data during distillation. For example, to find out how distillation affects translations of doctor, we had a close look at versions of the WMT19 English–German training data:
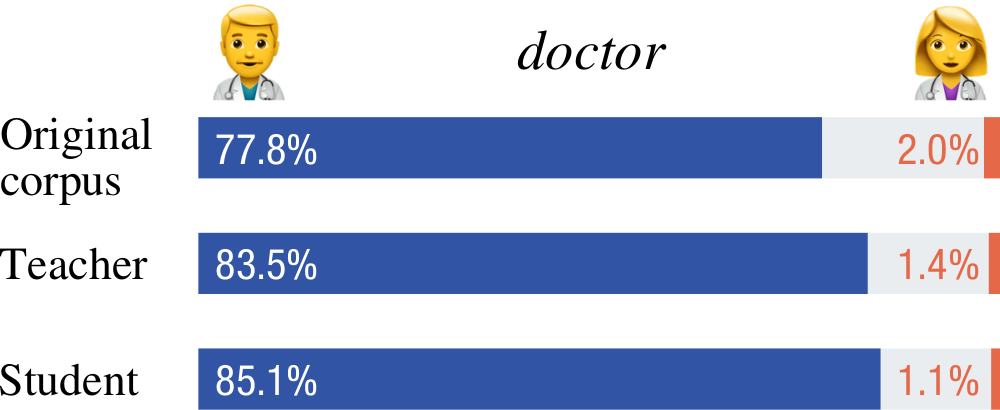
In the original training data (created by human translators over decades), doctor is mostly translated into male forms such as Arzt and rarely into female forms such as Ärztin. (The center represents word forms that we could not automatically classify as male or female forms based on grammatical gender.) The distilled training data produced by the teacher have an even stronger imbalance, and the student, when we fed it the same sources, created translations that overgeneralize even more.
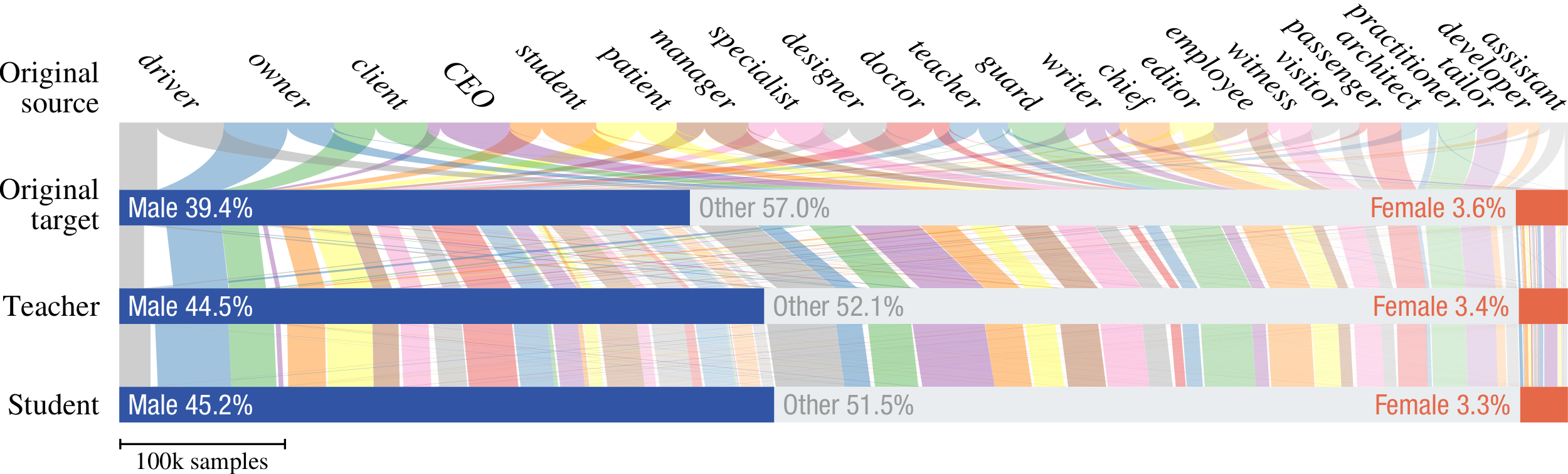
To see for yourself that this phenomenon is not specific to doctors, have a look at this Sankey diagram, which shows the same trend for 24 different occupations:
Results on Probing Tasks
A limitation of counting words is that there is no guarantee the context contains a clue about the correct translation. Many English source sentences might use the word doctor in an inherently ambiguous sense that would be impossible to disambiguate even for human translators. In that sense, we have so far only observed a weak form of overgeneralization.
To verify that distilled MT systems also have a strong overgeneralization bias (that they also tend to ignore the more salient contexts), we performed experiments using two probing datasets for word sense disambiguation: MuCoW (Raganato et al., 2019) and WinoMT (Stanovsky et al., 2019), and two language pairs (English–German and English–Russian). On top of the two datasets, we used a novel evaluation protocol called contrastive conditioning that allowed us to judge the 1-best translations of our models with a high recall.
Below I have included one of four graphs from the results (the others look similar and can be found in the paper).
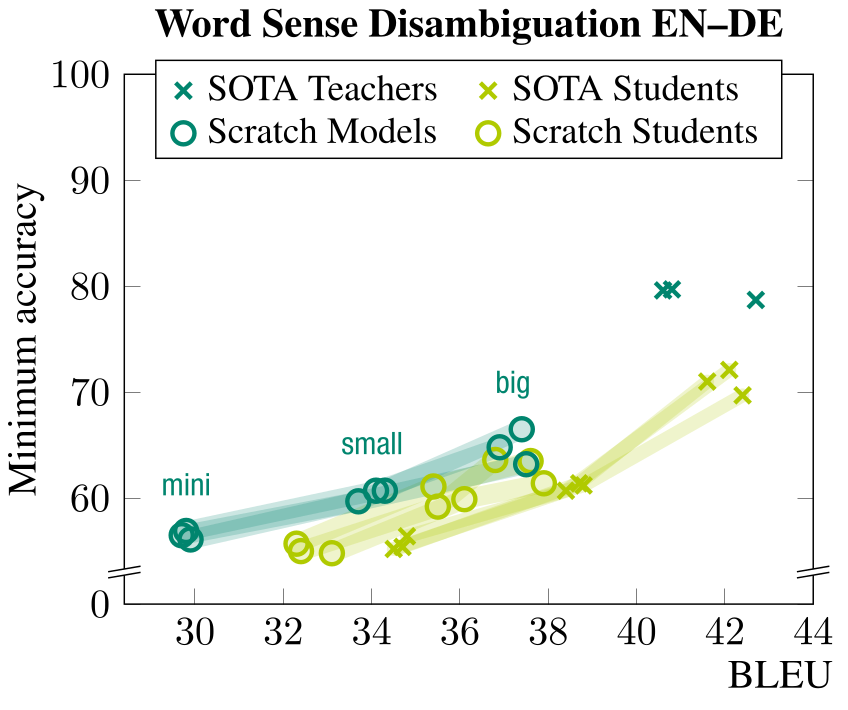 Accuracies of various English–German models, distilled and non-distilled, on word sense disambiguation.
Accuracies of various English–German models, distilled and non-distilled, on word sense disambiguation.
Our probing results confirm that distilled MT systems indeed have a higher overgeneralization bias than comparable non-distilled models, even if we control for BLEU. Another – expected – implication of the results is that BLEU scores do not capture overgeneralization bias reliably. It seems that to trace the effects of distillation in MT, targeted evaluation is needed as much as ever, and we hope that contrastive conditioning can contribute to it.
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 1317–1327. Austin, Texas, November 2016. Association for Computational Linguistics. URL: https://www.aclweb.org/anthology/D16-1139, doi:10.18653/v1/D16-1139. ↩
Alessandro Raganato, Yves Scherrer, and Jörg Tiedemann. The MuCoW test suite at WMT 2019: automatically harvested multilingual contrastive word sense disambiguation test sets for machine translation. In Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), 470–480. Florence, Italy, August 2019. Association for Computational Linguistics. URL: https://www.aclweb.org/anthology/W19-5354, doi:10.18653/v1/W19-5354. ↩
Gabriel Stanovsky, Noah A. Smith, and Luke Zettlemoyer. Evaluating gender bias in machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 1679–1684. Florence, Italy, July 2019. Association for Computational Linguistics. URL: https://www.aclweb.org/anthology/P19-1164, doi:10.18653/v1/P19-1164. ↩ 1 2
Chunting Zhou, Jiatao Gu, and Graham Neubig. Understanding knowledge distillation in non-autoregressive machine translation. In International Conference on Learning Representations. 2020. URL: https://openreview.net/forum?id=BygFVAEKDH. ↩