
In a paper presented at BlackboxNLP 2021, we highlight a limitation of minimal sentence pairs when it comes to predicting generative behavior, and propose a simple technique for improving their predictiveness. This blog post is a brief introduction.
Why minimal sentence pairs are useful
Minimal sentence pairs (Linzen et al., 2016) are frequently used for the contrastive evaluation of language generation models:

Sentences A and B differ in just one aspect. In Sentence A, there is agreement between the subject and the verb, whereas in Sentence B, the number of the verb disagrees with the subject. If a language model assigns a higher probability score to Sentence A and similar sentences than to Sentence B, this can be seen as a preference for subject-verb agreement.
A great advantage of minimal sentence pairs is that they allow to automate the evaluation of language models while isolating a specific linguistic phenomenon. But a question that has also been raised in previous work by Newman et al. (2021) is how much minimal pairs tell us about the generative behavior of a model.
Contrastive evaluation is based on a forced decision between two predefined sequences. However, at deployment time, end users are often exposed to the 1-best generated sequence, for example in machine translation or in dialogue. The sequence that end users are seeing might be completely different from the choices given to the model at evaluation time:

Contrastive evaluation in MT
In our paper, we set out to explore the limits of minimal pairs. In order to do that, we perform some experiments in the context of neural machine translation (NMT).
When evaluating NMT models, minimal pairs are used on the target side (Sennrich, 2017). Given a source sequence, two contrastive translation variants are presented to the model:

The example above shows two German translation variants for an English source sentence. Again, translation A preserves subject-verb agreement and translation B does not.
The probability score that is output by an NMT system is usually computed as the average log-likelihood of the target tokens, conditioned on the source sequence. It can be expected that a good NMT system assigns a higher score to the correct translation variant.
But do such minimal pairs always tell us how an NMT system will behave at deployment time?
Testing implausible hypotheses using minimal pairs
A straightforward way to explore the limits of such minimal pairs is to test an implausible hypothesis about the generative behavior of NMT systems.
In previous work, all the hypotheses that have been tested are more or less plausible, as for example the hypothesis that NMT systems observe subject-verb agreement. However, when we test some implausible hypotheses about generative behavior, we find that the results based on minimal pairs still produce some evidence for these implausible hypotheses.
Specifically, we look at two phenomena in the German language that are cognitive or social phenomena. The first implausible hypothesis is that NMT systems use vague language in the form of placeholder nouns very frequently. In spoken German, if someone doesn’t remember a noun, they might say ’Ding’ instead, which means ‘thing’ or ‘thingy’:

The second implausible hypothesis is that NMT systems are frequently producing hypercorrections. We look at hypercorrect genitives in German, where dative, rather than genitive, would be the more acceptable case for a preposition:

But why do we think that these phenomena are implausible? First of all, they are rarely found in the training data, so they would have to originate from somewhere else. In human speech, the phenomena are caused by cognitive and social factors, for example the tendency to forget a word when speaking, or the desire to attain social prestige. These factors do not apply to neural language models, making it implausible that they would produce the phenomena.
When creating test sets of minimal pairs for these phenomena, we find that our NMT systems do not reach 100 percent accuracy:
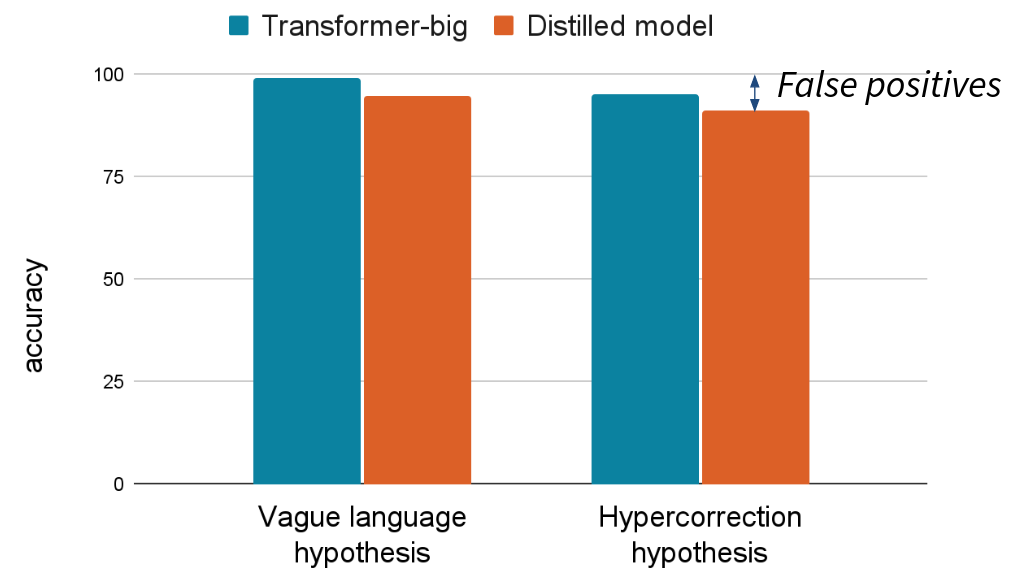
In other words, there are a certain number of instances where the NMT systems decide in favor of the translation containing vague language, or in favor of the translation containing a hypercorrection.
Taken at face value, these results would indicate that the NMT systems do generate the phenomena occasionally, and also that distilled NMT systems produce the phenomena more often than non-distilled models. But if you look at actual machine translations, you will almost never find the phenomena (since they are very implausible). So in this sense, minimal pairs would lead to false positives about the generative behavior of NMT systems, making comparisons between systems more difficult.
Some minimal pairs are more predictive than others
One reason why minimal pairs are not entirely predictive of generative behavior is that they are not among the translations that the NMT system would generate by itself, given the source sequence:

The 1-best translation has the highest probability score and is usually approximated using beam search in practice. In comparison, the contrastive variants of the minimal pair usually have a lower probability score.
One reason for that may be that they have been constructed by humans, and as such are sampled from a slightly different language distribution than what the system would generate by itself. This discrepancy might be especially large for distilled NMT systems, since they have never been exposed to human-written text during training.
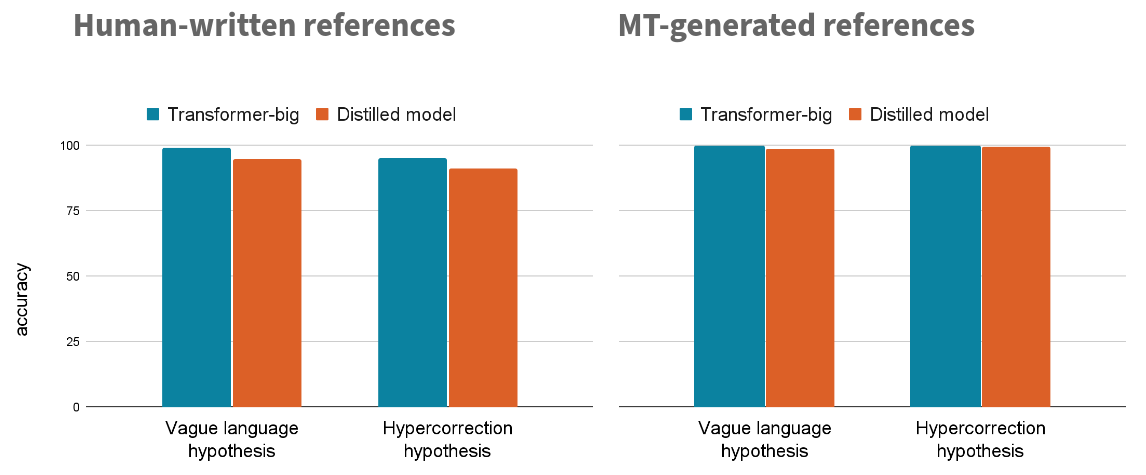
It seems reasonable to assume that a high discrepancy of minimal pairs can hurt their predictiveness. We checked this by creating a second set of minimal pairs from machine-generated references.
We translated the same source sequences we used before with a variety of commercial MT systems, and constructed minimal pairs based on the machine translations:

In the above example, the commercial MT system has output a translation with correct subject-verb agreement (A-MT). Like before, the incorrect variant can be created by changing the number of the verb (B-MT). If you happen to speak German, you will also notice that the machine translation uses slightly simpler expressions than the human translation (A).
When testing our two implausible hypotheses again, we now find that the test sets derived from machine-generated references produce fewer false positives, showing that these test sets are now more predictive of generative behavior:
The DistilLingEval test suite
The success that we had with machine-generated references inspired us to also release similar contrastive test sets for other linguistic phenomena.
DistilLingEval is a test suite for 8 linguistic phenomena in English→German translation. While similar to LingEval97, our test suite has been created based on machine-generated references. As such, we expect it to be more predictive when it comes to generative behavior. Have a look at the GitHub repo to find out more about the test suite.
Our hope is that in future work, similar test sets will be created for other tasks, languages and linguistic phenomena.
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. Assessing the ability of LSTMs to learn syntax-sensitive dependencies. Transactions of the Association for Computational Linguistics, 4:521–535, 2016. URL: https://aclanthology.org/Q16-1037, doi:10.1162/tacl_a_00115. ↩
Benjamin Newman, Kai-Siang Ang, Julia Gong, and John Hewitt. Refining targeted syntactic evaluation of language models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 3710–3723. Online, June 2021. Association for Computational Linguistics. URL: https://aclanthology.org/2021.naacl-main.290, doi:10.18653/v1/2021.naacl-main.290. ↩
Rico Sennrich. How grammatical is character-level neural machine translation? Assessing MT quality with contrastive translation pairs. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 376–382. Valencia, Spain, April 2017. Association for Computational Linguistics. URL: https://aclanthology.org/E17-2060. ↩