
While neural machine translation (NMT) is mainly being used for translating text, it is also useful for comparing text. This bonus feature of NMT is promising for some areas where attention to detail matters. We have released a new Python library as well as a paper accepted to Findings of EMNLP 2022 that compares translation-based similarity measures to baselines such as sentence embeddings.
In this post I summarize our findings.
The concept of translation probability
At the core of an NMT system, there is a translation model that estimates the probability of any translation, given the source sequence. For example, a good translation model will tell us that "Bonjour" can probably be translated into English as "Hello", but that "Goodbye" would be an improbable translation.
Let me demonstrate this using our Python library, NMTScore. First, let's download an open-source NMT model from HuggingFace:
from nmtscore.models import load_translation_model
model = load_translation_model("m2m100_418M")
This model, called M2M100, has been released by Fan et al. (2021). Let's ask the model to estimate some translation probabilities for us:
model.score("en", ["Bonjour !"], ["Hello to you!"])
# [0.35]
model.score("en", ["Bonjour !"], ["Sleep well!"])
# [0.11]
The first argument tells the model about the target language. Of course, if the target language were German instead of English, the translation would become less probable:
model.score("de", ["Bonjour !"], ["Hello to you!"])
# [0.04]
Multilingual translation models
Which brings us to the concept of a multilingual translation model. Multilingual models are trained jointly on multiple source languages and/or target languages. For example, M2M100 is a many-to-many model that translates between no less than 100 languages.
As shown above, a multilingual model only needs to know the target language, but it can infer the source language by itself. For example, we can create a translation from Swedish without explicitly telling the model that the input is Swedish:
model.translate("en", ["Hej Hanna, hur är läget?"])
# ['Hi Hanna, how is it?']
This is an interesting property, and a side effect is that the input language is allowed to be identical to the target language:
model.translate("en", ["Hi Hanna, how are you?"])
# ['Hi Hanna, how are you?']
The above is sometimes called zero-shot paraphrasing (Thompson and Post, 2020).
Different ways to compare two sentences
The basic principle behind NMTScore is that translation probabilities can be used to compare two sentences. For example, "Hello", "Good day", "Bonjour, and "Hej" all have similar meaning. On the other hand, "Hello", "Sleep well" and "Schadenfreude" are not similar with respect to their meaning.
In the past, researchers have already come up with creative ways of leveraging NMT to compare a sentence A to a sentence B:
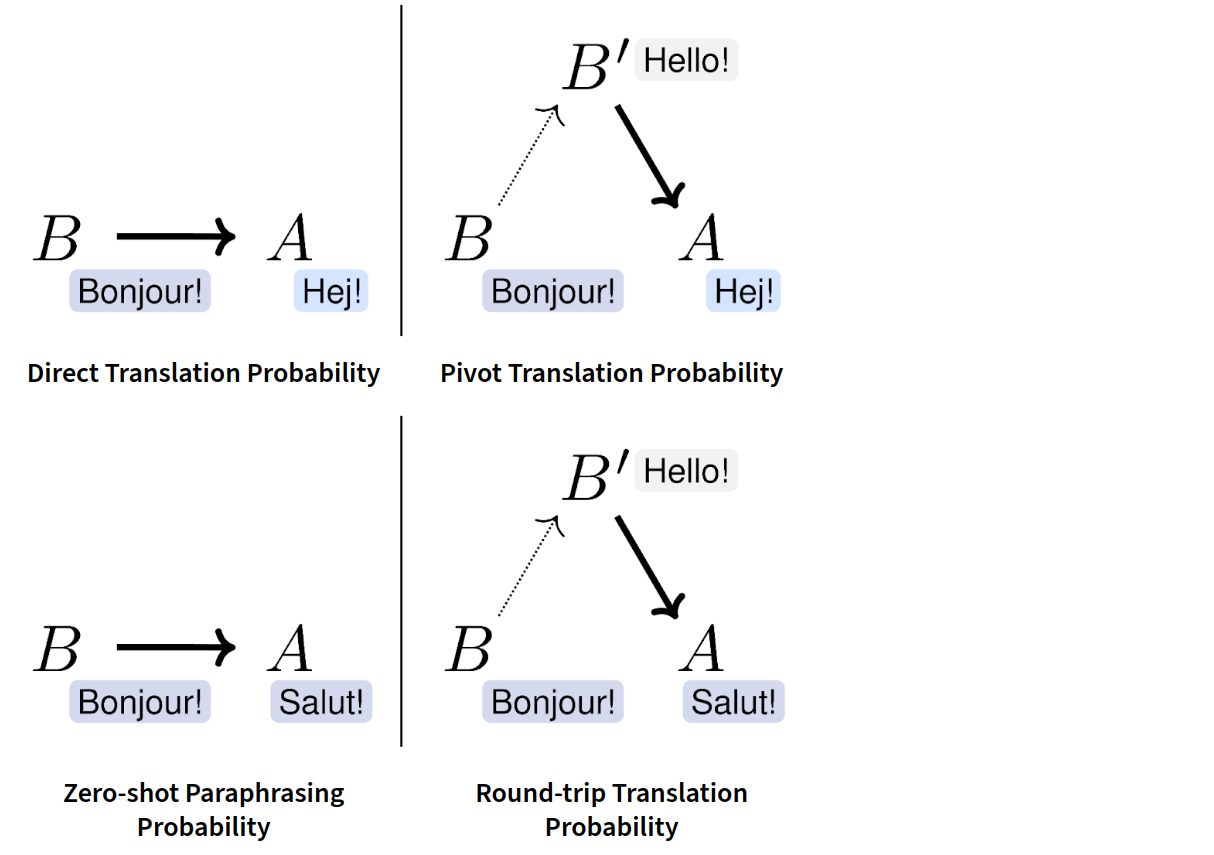
For example, the translation probability of A given B can be used directly as a similarity measure (left-hand side; JunczysDowmunt (2018), Thompson and Post (2020)). Alternatively one can also estimate the probability that A is a translation of B via a pivot language, and use that as a similarity measure (right-hand side; Mallinson et al. (2017)).
Both approaches are useful if A and B are in two different languages (upper row), and also if A and B are in the same language (bottom row). The reason for that is that multilingual NMT models do not need to know the language of their input.
When creating the matrix above, we found that an interesting variant has not been tried before, and we added that column to the matrix:
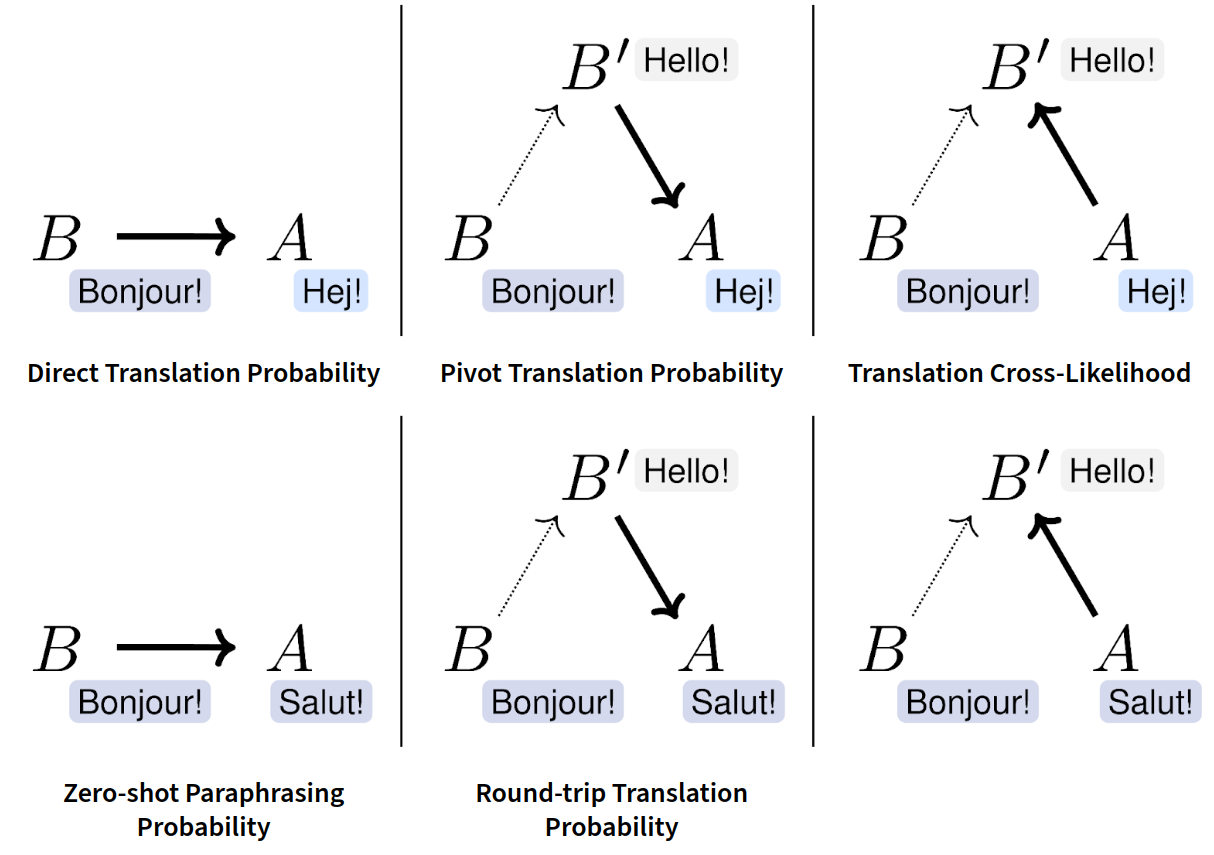
The idea of translation cross-likelihood is that both A and B are translated into a target language (e.g. English). Specifically, we ask the model whether a translation of B could also be a good translation of A.
Again, this approach works both for sentences in the same language, and cross-lingually. The translation cross-likelihood measure has some other nice properties. For example, it is somewhat more symmetrical.
Advantages of translation-based text similarity
In our paper, we evaluate the different variants of NMTScore in two settings: multilingual paraphrase identification, and multilingual reference-based evaluation of generated text.
The goal of the former is to find out whether two sentences are paraphrases of each other. A similarity measure has high accuracy if it assigns higher similarity to the paraphrases in a dataset than to the non-paraphrases.
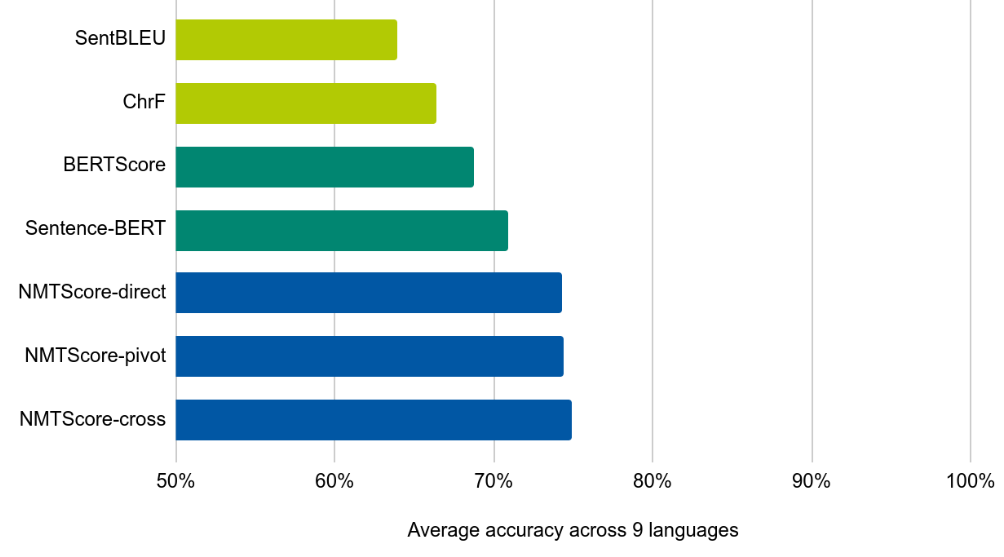
Overall, we found that NMTScore is competitive compared to common baselines such as embeddings derived from a pre-trained language model. We also propose a normalization scheme, called reconstruction normalization, and we show that it contributes to the high accuracy of NMTScore.
NMTScore is especially good with adversarial examples, where deceptively similar sentences pairs need to be distinguished (Zhang et al., 2019):
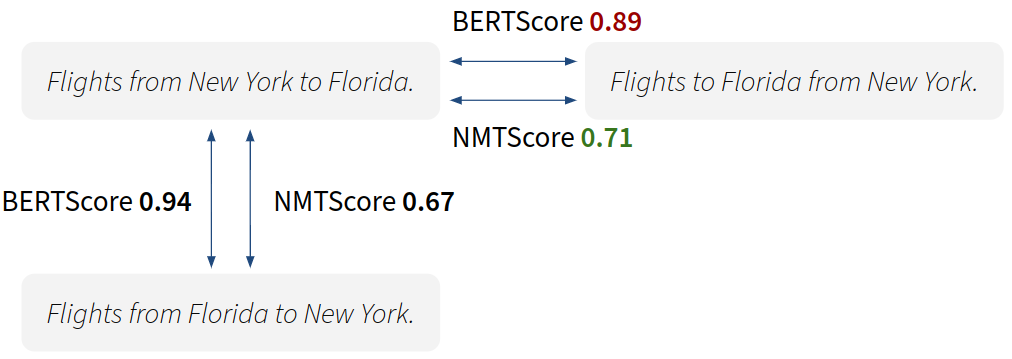
Here's the code to reproduce the figure:
from nmtscore import NMTScorer
scorer = NMTScorer("prism")
scorer.score(
"Flights from New York to Florida.",
"Flights from Florida to New York.",
)
# 0.67
scorer.score(
"Flights from New York to Florida.",
"Flights to Florida from New York.",
)
# 0.71
In the second evaluation setting – reference-based evaluation – we find a competitive performance to the baselines. This is especially relevant to NLP researchers who evaluate and compare text generation systems such as data-to-text systems. The researchers often use similarity measures (like BLEU) to compare the system output to a reference output, and NMTScore seems to be a relatively reliable choice for such a measure.
Outlook
Our library is available on GitHub. If you'd like to share a use case or a suggestion, please create an issue to let us know.
In summary, NMTScore and its variants are an attractive complement to other similarity measures. Keep in mind, however, that the open-source NMT models we use perform especially well with shorter text segments, and do not support all language pairs equally well.
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Michael Auli, and Armand Joulin. Beyond english-centric multilingual machine translation. Journal of Machine Learning Research, 22(107):1–48, 2021. URL: http://jmlr.org/papers/v22/20-1307.html. ↩
Marcin Junczys-Dowmunt. Dual conditional cross-entropy filtering of noisy parallel corpora. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, 888–895. Belgium, Brussels, October 2018. Association for Computational Linguistics. URL: https://aclanthology.org/W18-6478, doi:10.18653/v1/W18-6478. ↩
Jonathan Mallinson, Rico Sennrich, and Mirella Lapata. Paraphrasing revisited with neural machine translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, 881–893. Valencia, Spain, April 2017. Association for Computational Linguistics. URL: https://aclanthology.org/E17-1083. ↩
Brian Thompson and Matt Post. Automatic machine translation evaluation in many languages via zero-shot paraphrasing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 90–121. Online, November 2020. Association for Computational Linguistics. URL: https://aclanthology.org/2020.emnlp-main.8, doi:10.18653/v1/2020.emnlp-main.8. ↩ 1 2
Yuan Zhang, Jason Baldridge, and Luheng He. PAWS: paraphrase adversaries from word scrambling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1298–1308. Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. URL: https://aclanthology.org/N19-1131, doi:10.18653/v1/N19-1131. ↩