
This blog post is a brief introduction to a paper presented at ACL 2022, titled "As Little as Possible, as Much as Necessary: Detecting Over- and Undertranslations with Contrastive Conditioning".
Coverage errors in MT
Neural machine translation (NMT) has greatly improved over the last years, but there are still a few typical errors that afflict NMT even in high-resource language pairs. One common error type is addition or omission of content, which is also sometimes called overtranslation or undertranslation, or simply an error of incomplete coverage.
For example, a commercial MT system has recently translated the following English sentence into German (source):

German speakers can confirm that the output sounds fluent. However, the phrase “reeling from low oil prices” has not been translated, and so a crucial piece of information is missing in the translation.
Contrastive Conditioning
In a short paper presented at ACL 2022, we propose a new method for automatically identifying such coverage errors.
The approach that we use is contrastive conditioning, and I have written about it in a previous blog post. We had developed it originally to detect word sense disambiguation errors.
Our idea was to score a translation conditioned on contrastive source sequences. If the translation looks probable for a given source sequence, the latter can tell us something about the translation:

In other words, we try to infer properties of a translation by trying different hypothetical source sequences and checking which ones are most plausible for the translation. This can be done automatically, using an off-the-shelf NMT system.
Minimal Example
In this paper, we use contrastive conditioning to detect coverage errors. Let me demonstrate this on the example of a short, made-up translation:

This translation contains an omission error: The phrase “after landing” seems to have been lost in translation.
Our idea is that this could be detected by conditioning the translation on another, hypothetical source sequence. Specifically, we expect that the source sequence “Please exit the plane” should have a higher likelihood than the actual one.
So let’s take an open-source NMT model and verify:

Indeed, the NMT model assigns a higher probability to the hypothetical source sequence that does not contain “after landing”.
Note that we could use any NMT model for this. It could be the same system that created the translation, but does not have to be.
Searching for Errors
After this proof of concept, let's try if we can spot other omission errors with this method – beyond this made-up example.
When analyzing a translation, we perform an exhaustive search over all the phrases that might be missing in the translation, and we compare the translation probability conditioned on a partial source sequence (which the phrase removed) to the probability conditioned on the original source sequence:

I have grayed out partial sources that can be skipped, since these parts of speech are unlikely to give useful results.
(For example, the article “the” is not a content word, and it is unlikely that there is a coverage error involving just an article. After all, we are mainly interested in so-called constituents, which are sometimes defined as word spans that can be removed from a sentence without rendering it ungrammatical. We approximate the concept of constituents by creating a dependency tree and only selecting nodes that meet certain conditions.)
Checking for addition errors can be done in an analogous way:

We estimate the reverse probabilities using an NMT model that translates in the reverse direction. In the above example, no partial source has a higher likelihood that the original source, since the translation does not contain an addition error.
Real-world Example
Finally, let's apply the algorithm to the real-world example I mentioned at the beginning of this post, where “reeling from low oil prices” was missing in a lengthy sentence. I'm going to use our Python implementation:
from coverage.evaluator import CoverageEvaluator
from translation_models import load_forward_and_backward_model
forward_model, backward_model = load_forward_and_backward_model("mbart50", src_lang="en", tgt_lang="de")
evaluator = CoverageEvaluator(
src_lang="en",
tgt_lang="de",
forward_evaluator=forward_model,
backward_evaluator=backward_model,
)
src = "The government, reeling from low oil prices, says it hopes tourism will contribute up to 10 percent of the gross domestic product by 2030, compared to three percent currently."
translation = "Die Regierung hofft, dass der Tourismus bis 2030 bis zu 10 Prozent des Bruttoinlandsprodukts ausmachen wird, verglichen mit derzeit drei Prozent."
result = evaluator.detect_errors(src, translation)
print(result)
# Omission errors: reeling from low oil prices | from low oil prices | low | oil
Looking at the output, it seems that the missing phrase is correctly identified.
Evaluation Results
In the paper, we describe how we evaluated our approach on a dataset of real-world machine translation errors created by Freitag et al. (2021). We also perform a human evaluation of word-level precision, in order to better understand what our algorithm gets right and when it fails. The language pairs we evaluate on are English–German and Chinese–English.
As a supervised baseline we use a token classification system (based on XLM-Roberta) that outputs whether a source token is omitted in the translation, and whether a target token is an addition error. This approach is based on previous work on token-level quality estimation and was implemented with OpenKiwi (Kepler et al., 2019). We trained the supervised baseline on a large-scale dataset of synthetic coverage errors. In the paper we describe in more detail how we created this dataset, and we release it alongside the code on GitHub.
On the segment level we find that our algorithm has similar or higher accuracy than the supervised baselines. It is especially accurate for omission errors:
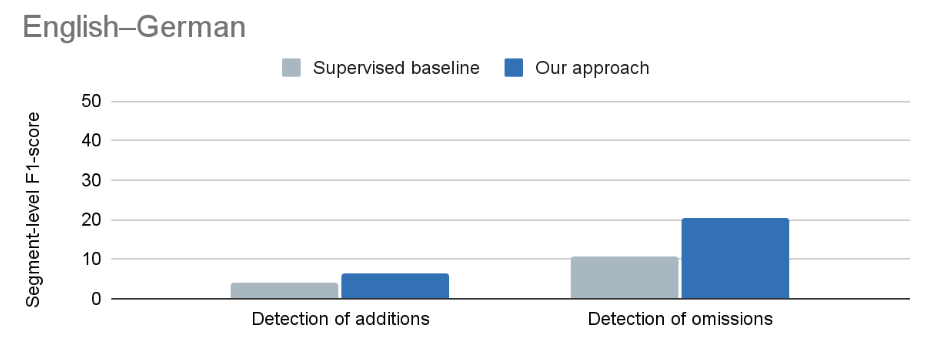
Regarding addition errors, the accuracy of both methods is likely too small to be helpful. But there are fewer positive examples of addition errors in the dataset, which makes it difficult to achieve a high accuracy.
The human evaluation shows us that the word-level precision is comparable to the segment-level accuracy. And it turns out a portion of the detected word spans are actually different types of errors:
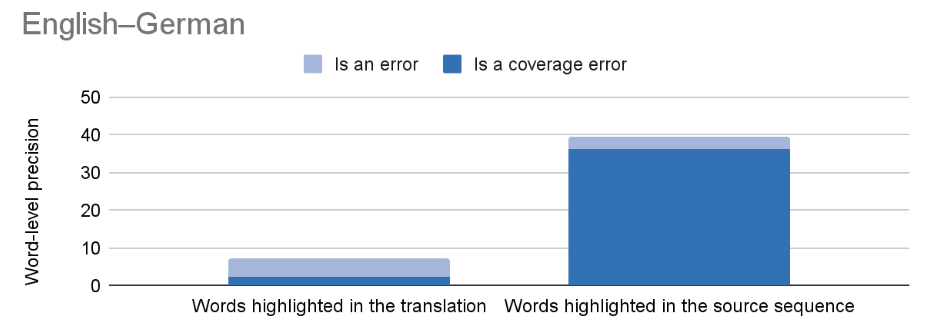
The light blue area in the figure means that a detected word span is indeed a translation error, but it is e.g. an accuracy error and not a coverage error. There is also a large amount of false positives, where our human annotators did not find anything wrong with the highlighted word spans, especially with addition errors. In our paper, we show examples for these phenomena.
Summary
We have demonstrated a reference-free method to automatically detect coverage errors in translations. Specifically, our method relies on hypothetical reasoning using contrastive conditioning.
An advantage of our approach is that it does not require a specifically trained model, such as a quality estimation model. Instead we use an off-the-shelf NMT model, which could also be the model that originated the translation in the first place.
Given the encouraging accuracy on omission errors, it would be interesting to see user studies on whether their automatic detection could aid translators and post-editors. On the other hand the detection of addition errors seems to be more challenging, and is still an open problem.
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Markus Freitag, George Foster, David Grangier, Viresh Ratnakar, Qijun Tan, and Wolfgang Macherey. Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation. Transactions of the Association for Computational Linguistics, 9:1460–1474, 12 2021. URL: https://doi.org/10.1162/tacl\_a\_00437, arXiv:https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl\_a\_00437/1979261/tacl\_a\_00437.pdf. ↩
Fabio Kepler, Jonay Trénous, Marcos Treviso, Miguel Vera, and André F. T. Martins. OpenKiwi: an open source framework for quality estimation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 117–122. Florence, Italy, July 2019. Association for Computational Linguistics. URL: https://aclanthology.org/P19-3020, doi:10.18653/v1/P19-3020. ↩