
Last year, I announced SwissBERT, a multilingual encoder model that we trained on news articles from Switzerland.
At the time, we found that SwissBERT had good accuracy on Switzerland-related NLP tasks such as named entity recognition and stance detection, compared to similar models that were not trained on those data. We were especially impressed by the model's performance on Romansh input text, for which we had little training data and for which no previous language model existed.*
A limitation of SwissBERT is that it has only been trained on news articles. In Switzerland, there is a stark difference between Standard German, as used in newspapers, and Swiss German dialect. Dialect is not traditionally written, but has become ubiquitous on social media, in text messages and other informal contexts:
Super happy für min @FC_Basel 3-0 super Resultat! Das git mir so richtig lust uf min match morn im halbfinal!!! #Dangge
— Roger Federer (@rogerfederer) February 27, 2014
An ideal encoder model for Switzerland should thus be able to process written text in both Standard German and Swiss German (in addition to Romansh, French, and Italian).
Adding Swiss German to SwissBERT
In a new paper that we present at the MOOMIN Workshop on Modular and Open Multilingual NLP, we propose an updated version of SwissBERT that can do just that. We trained the model on two new datasets:
- SwissCrawl (Linder et al., 2020), a collection of Swiss German web text (forum discussions, social media).
- A dataset of Swiss German tweets that I collected during my master studies at LMU Munich.
We evaluated the model on three Swiss German tasks and found that adding Swiss German to the training data generally leads to a clear improvement in accuracy:

The updated model is available on the Hugging Face hub. Note that due to the data licenses, use of the model is restricted to research purposes.
Modular Adaptation through Adapters
In an earlier post, I described the modular architecture that we used for SwissBERT, called X-MOD (Pfeiffer et al., 2022). The idea is to have a single encoder model that can be adapted to different languages by adding a language adapter module for each language. The adapter is activated only when the model is processing input in the given language.
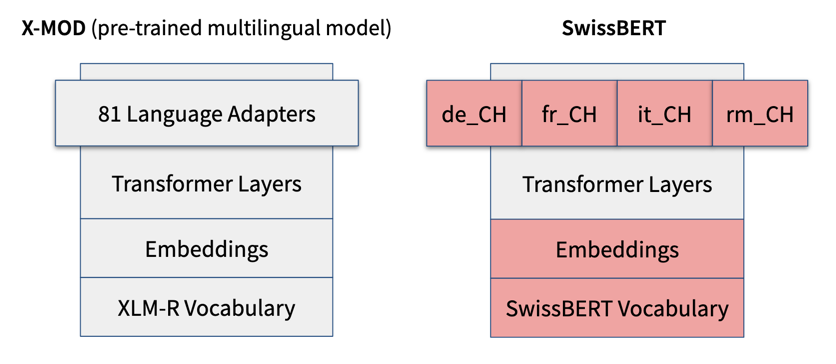
The original SwissBERT model has four language adapters for the four national languages of Switzerland (de_CH = Swiss Standard German, fr_CH = French, it_CH = Italian, rm_CH = Romansh Grischun).
Adding Swiss German to the model is straightforward: We simply add a fifth adapter for Swiss German (gsw). All the other modules stay exactly the same:
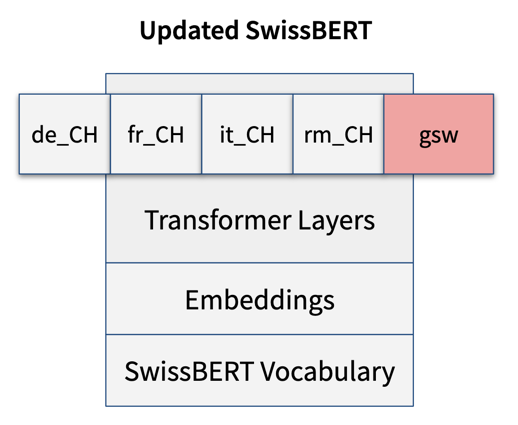
We compared this strategy to a baseline where we update the Transformer layers and embeddings as well, when we train on Swiss German. We found that our modular approach reaches 97.5% of the accuracy of the baseline, while the multilinguality of the model is guaranteed to be preserved.
More Findings 🤓
In the paper, we perform some more experiments – beyond SwissBERT – which are especially relevant if you're planning to train your own model on Swiss German. Here's the highlights:
- XLM-R is a surprisingly good baseline. Obviously, the multilingual model XLM-R (Conneau et al., 2020) does not work well with Swiss German, because it was never trained on text in this language. However, if we just continue the pre-training of XLM-R on our Swiss German dataset, the average accuracy is actually higher than that of the adapted SwissBERT. We release our Swiss German XLM-R model here.
- Character-level modeling is good for cross-lingual retrieval. The spelling of Swiss German text is highly variable, which motivated us to also try adapting a multilingual character-level model. We adapted CANINE (Clark et al., 2022) to Swiss German and found that on part-of-speech tagging, it achieves a much lower accuracy than the subword-based XLM-R and SwissBERT models. But CANINE achieves the best accuracy on the sentence retrieval task, which to us was surprising and could be an inspiration for future work. The Swiss German CANINE model is available here.
- A custom Swiss German subword vocabulary is not beneficial. Given the spelling differences between Standard German and Swiss German, one might think that a custom subword vocabulary is needed for Swiss German. However, we found that re-using the existing vocabularies of XLM-R and SwissBERT worked better. In addition to the spelling variation in Switzerland, which might make compression harder, another likely reason is that the Swiss German dataset is relatively small, so the model might not be able to learn good word embeddings from scratch.
Equipped with a Swiss German adapter, the SwissBERT model is now a more complete text encoder and covers not only the four national languages of Switzerland, but also a family of dialects that is spoken (and written) by 5 million people in Switzerland.
*You might ask: Couldn't ChatGPT do these tasks as well? Yes, maybe it could. But an encoder like SwissBERT is a lot smaller, and, as of today, much faster. One use case where efficiency is important is processing a large document collection, e.g., for creating an embedding-based search index. Such an index is often needed for enabling retrieval augmentation of large language models.
The work presented in this post is joint work with Noëmi Aepli and Rico Sennrich. It was funded by the Swiss National Science Foundation (project nos. 213976 and 191934).
References
Jonathan H. Clark, Dan Garrette, Iulia Turc, and John Wieting. Canine: Pre-training an Efficient Tokenization-Free Encoder for Language Representation. Transactions of the Association for Computational Linguistics, 10:73–91, 01 2022. URL: https://doi.org/10.1162/tacl\_a\_00448, arXiv:https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl\_a\_00448/1985933/tacl\_a\_00448.pdf, doi:10.1162/tacl_a_00448. ↩
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 8440–8451. Online, July 2020. Association for Computational Linguistics. URL: https://aclanthology.org/2020.acl-main.747, doi:10.18653/v1/2020.acl-main.747. ↩
Lucy Linder, Michael Jungo, Jean Hennebert, Claudiu Cristian Musat, and Andreas Fischer. Automatic creation of text corpora for low-resource languages from the internet: the case of swiss german. In Proceedings of The 12th Language Resources and Evaluation Conference, 2706–2711. Marseille, France, May 2020. European Language Resources Association. URL: https://www.aclweb.org/anthology/2020.lrec-1.329. ↩
Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, and Mikel Artetxe. Lifting the curse of multilinguality by pre-training modular transformers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 3479–3495. Seattle, United States, July 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.naacl-main.255, doi:10.18653/v1/2022.naacl-main.255. ↩