
Self-supervised text encoders such as BERT are an important tool for natural language processing (NLP) applications. You won’t see them chatting away on the web like some large-scale generative models. But they are useful for NLP practitioners because they can be trained with mere billions, rather than trillions, of words, and they lend themselves to supervised fine-tuning.
After the original BERT model was released for English, many others were created, like CamemBERT for French and GilBERTo for Italian. Now, a team at the University of Zurich is adding another one to the list: We release SwissBERT, the multilingual language model for Switzerland.
SwissBERT supports Swiss Standard German, French, Italian and Romansh Grischun. It might even be extended to Swiss German dialects in the future.
Why wasn’t there a unified model for the Swiss national languages until now? A reason is that Switzerland is a multilingual country, and multilinguality is still a challenge in NLP. While there are plenty of training data available on the web for German, French, and Italian, there are little data for Romansh. Making sure that the higher-resource languages do not drown out the other languages in the model is non-trivial.
Another consideration is that there are already open-source models for three out of the four languages. Ideally, one could somehow combine these existing resources, adapt them to the peculiarities of Switzerland and add Romansh to the mix. Figuring out how to apply such a “Swiss Finish” has been another challenge.
To tackle these challenges, we used an approach from the recent literature: language-specific model components, or simply: language adapters. An advantage of language adapters is that each language has a reserved module of equal capacity. Each language adapter is activated only if the model processes input in the given language.
Specifically, we based SwissBERT on a massively multilingual model, X-MOD, which has been pre-trained with language adapters from scratch by Pfeiffer et al. (2022):
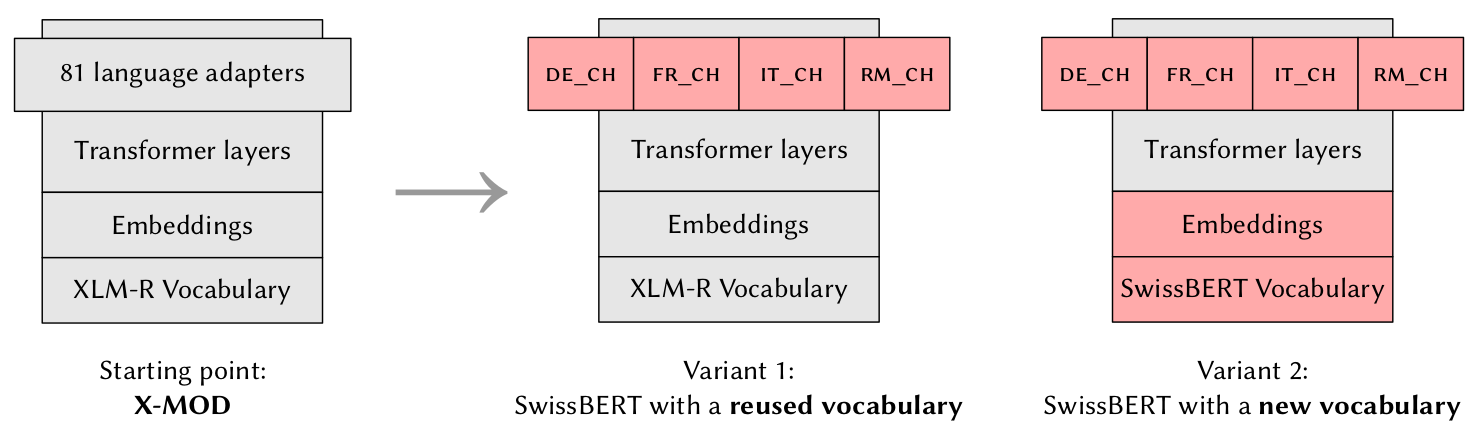
We trained the existing German, French and Italian adapters as well as a new Romansh adapter on 21 million news articles from Switzerland. Testing out two design variants, we found that a custom vocabulary and custom trained word embeddings (Variant 2 on the right) are better suited for the Swiss national languages than those of the massively multilingual X-MOD.
The 21 million news articles have been retrieved from Swissdox@LiRI, which provides access to many newspapers in the Swiss Media Database (SMD). Thus, rather than crawling the web, we had the chance to use a high-quality and clearly defined corpus for pre-training.
After ten passes through the pre-training corpus, we evaluated SwissBERT on a range of NLP tasks related to Switzerland. We first wanted to see how well it handles the sort of text it has been pre-trained on: contemporary news from Switzerland. We also looked into slightly different text domains to gauge the general performance of the model.
To evaluate our model on named entity recognition (NER), we created a collection of small-scale test sets for the four national languages.
Below is an example for the expected output of NER:

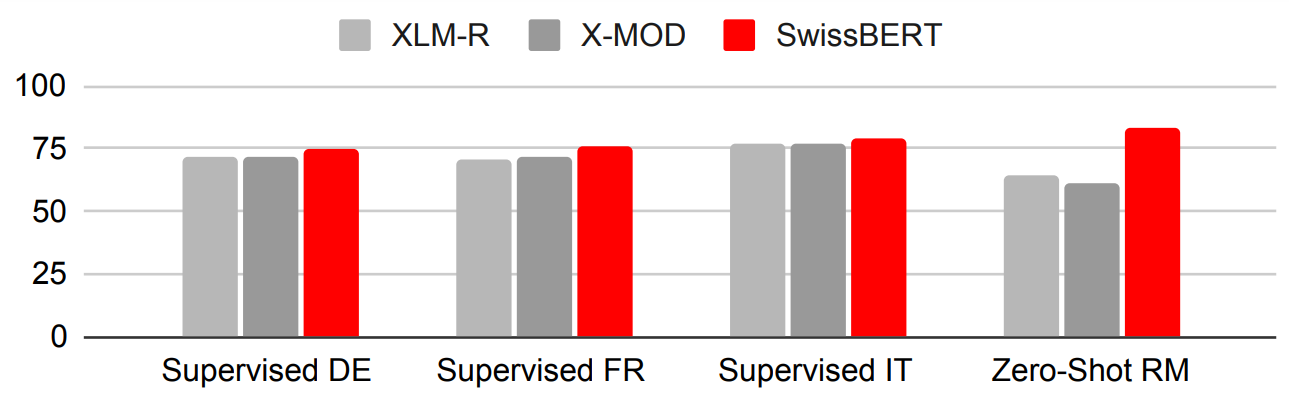
We were pleased to see that SwissBERT clearly outperforms the baselines on our test sets, both in terms of supervised NER (German, French and Italian) and zero-shot cross-lingual transfer (Romansh):
Another nice result is that SwissBERT performs unsupervised alignment of Romansh text to German text (Dolev, 2022) much more accurately than previous models, which have not been trained on Romansh:
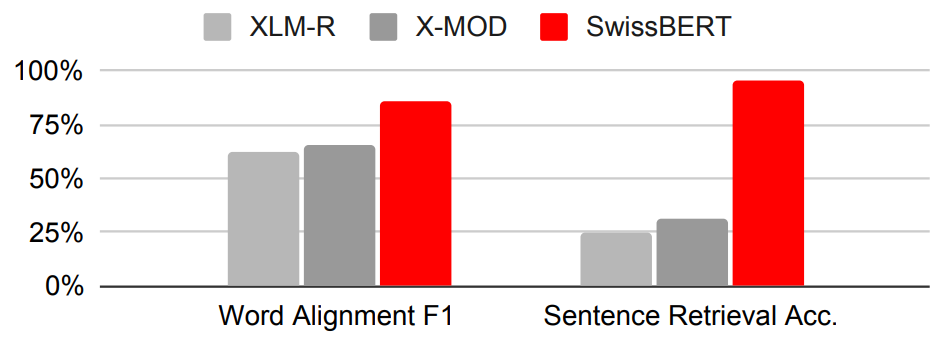 In other words, SwissBERT is good at comparing Romansh sentences to German sentences and identifying similar and dissimilar words and phrases.
The same probably holds for other language combinations.
In other words, SwissBERT is good at comparing Romansh sentences to German sentences and identifying similar and dissimilar words and phrases.
The same probably holds for other language combinations.
We also evaluated on cross-lingual classification of political comments (which works well) as well as NER for historical newspapers (which does not work too well with SwissBERT). The complete results are documented in our paper pre-print.
Given the encouraging results, we hope that our model can support researchers who need to analyze large amounts of contemporary written text in one of the Swiss national languages. Due to the nature of the pre-training corpus, we release the model with the CC BY-NC 4.0 license for now. This means that it can immediately be used by academic researchers, but not (yet?) for commercial applications.
The work presented in this post is joint work with Johannes Graën of UZH's Linguistic Research Infrastructure (LiRI) and my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Eyal Dolev. Using multilingual word embeddings for similarity-based word alignments in a zero-shot setting. tested on the case of German–Romansh. Master's thesis, Department of Computational Linguistics, University of Zurich, 2022. ↩
Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, and Mikel Artetxe. Lifting the curse of multilinguality by pre-training modular transformers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 3479–3495. Seattle, United States, July 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.naacl-main.255, doi:10.18653/v1/2022.naacl-main.255. ↩