
Update (2020-08-01): A video of the conference presentation is now available.
Automated stance detection systems try to detect broad opinions in natural language expressions. This post is an introduction to a new resource for stance detection called
Background: Stance Detection
The idea behind stance detection is best explained in an example. This tweet has recently earned more than 2 million likes:
After stoking the fires of white supremacy and racism your entire presidency, you have the nerve to feign moral superiority before threatening violence? ‘When the looting starts the shooting starts’??? We will vote you out in November. @realdonaldtrump
— Taylor Swift (@taylorswift13) May 29, 2020
Of course, the tweet does not just constitute a neutral election forecast. It also expresses a negative stance towards Donald Trump.
The type of stance detection system we are interested in is a system that takes an input text and a target and outputs either favor, against or neutral:

Stance detection systems have been made possible by a series of annotated datasets – from a collection of English tweets on Donald Trump and other topics all the way to a collection of Italian tweets on the Italian constitution.
However, it has been unclear if the systems can generalize well beyond those specific settings. For example, an English system is not necessarily applicable to Italian or French tweets. And if a system trained on the target of Donald Trump does not generalize to future presidents, then the data collection effort might not be very sustainable.
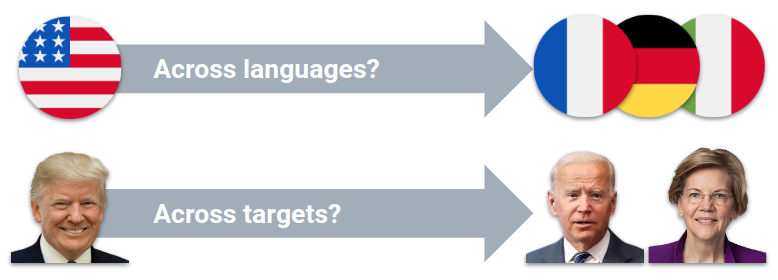 The generalization problem in stance detection. The two dimensions of transfer have been studied individually (Mohammad et al. (2016), Taule et al. (2017), Taule et al. (2018)), but not jointly.
The generalization problem in stance detection. The two dimensions of transfer have been studied individually (Mohammad et al. (2016), Taule et al. (2017), Taule et al. (2018)), but not jointly.
In x-Stance: A Multilingual Multi-Target Dataset for Stance Detection, we present a large-scale dataset in 3 languages and on more than 150 political issues. We show that x-Stance can be used to train a single model on all of those issues.
We also look at generalization performance: Our models are evaluated both in a held-out language and on held-out targets. We find that if a standard text classification model is used, zero-shot cross-lingual and cross-target transfer is moderately successful.
How We Created x-Stance
x-Stance contains 67,000 samples, which is an order of magnitude more than what has been common in stance detection. The dataset is relatively large because instead of doing manual annotation, we have extracted the data directly from a political website. The website – smartvote.ch – is a voting advice application that is highly popular in Switzerland.
Electoral candidates who participate in such a voting advice application are asked a range of questions on controversial topics. Should cannabis use be legalized? Should Switzerland strive for a free trade agreement with the United States?
What makes this website so interesting for stance detection is that the candidates can respond in two ways: On a yes/no scale and in a free-text comment:
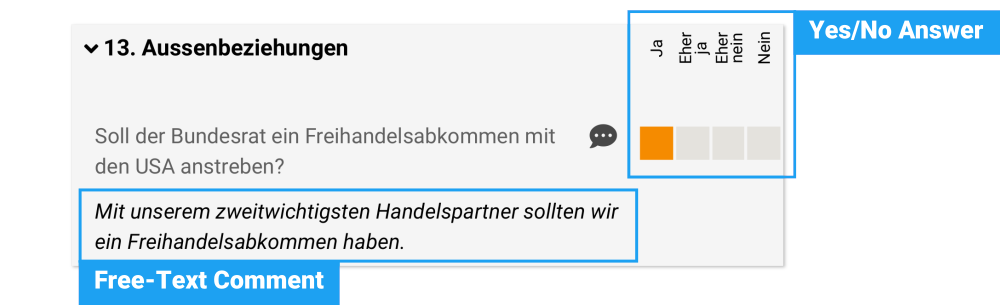 A part of a candidate's response on smartvote.ch.
A part of a candidate's response on smartvote.ch.
While it is not mandatory, candidates often like to write a few sentences in order to justify, explain or differentiate the yes/no answer in their own language. If we now reverse this relation and interpret the yes/no answer as an annotation of the comments, we receive a supervised data set for stance detection:

Such an automatically extracted dataset is likely noisier than manually curated datasets, but we still expect it to be useful for machine learning research. And thanks to the Smartvote team, we can make it available to fellow researchers under the CC BY-NC 4.0 license.
Apart from stance detection as a supervised task, we believe that the x-Stance is also a valuable resource for the study of transfer learning.
Putting the «x» in x-Stance : Transfer Learning
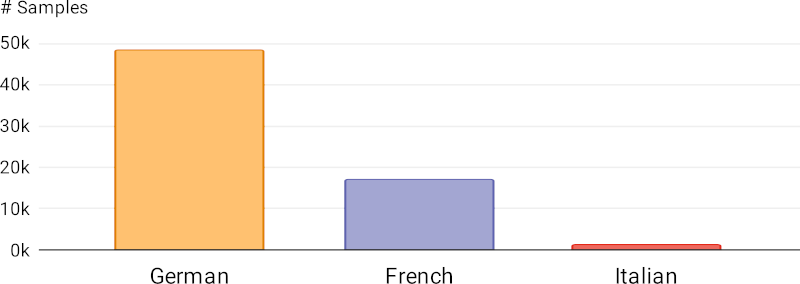
First of all, x-Stance is a multilingual dataset: Since different languages are spoken in different parts of Switzerland, candidates have been free to answer in any language, be it German, French or Italian. (To our regret we did not encounter any Romansh comments).
Secondly, the x-Stance dataset contains questions on diverse policy issues. We have clustered the questions into 12 broad topics, including 2 held-out topics:
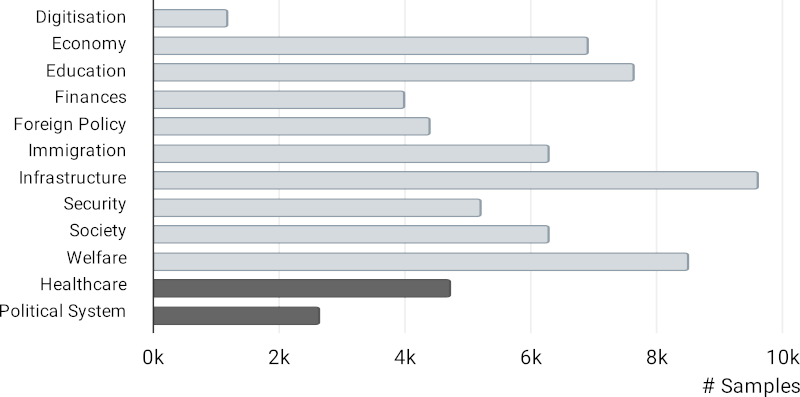
We can now test both for cross-lingual transfer from German and French to Italian, and for cross-target transfer from known topics to previously unseen topics such as healthcare:

In our paper we use a standard architecture – BERT – to demonstrate how x-Stance can serve as a benchmark for transfer learning.
Adapting BERT to x-Stance
We download the multilingual BERT model, which has been pre-trained by Google Research in 104 languages. We then fine-tune the model on our German and French training data.
As we want to train the model jointly on multiple targets (Free Trade, Legality of Cannabis, …), we need to inform the model about the specific target of every instance. For this we concatenate to each comment the corresponding natural-language question from Smartvote.
As BERT allows for two input segments, we designate the question as segment A and the comment as segment B. We put a linear classifier on top of BERT and train the model to predict either FAVOR or AGAINST given a question–comment pair:
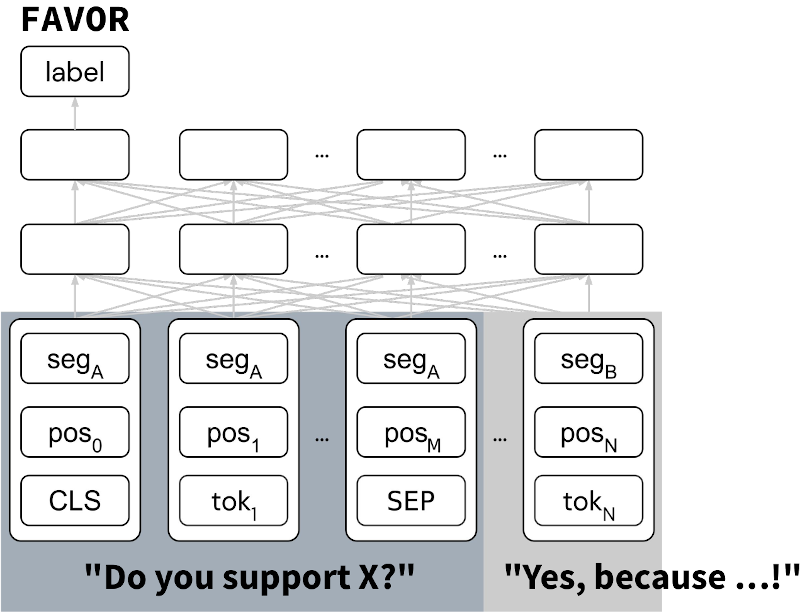 Input and output of a BERT sequence pair classifier. Original image by Artetxe et al. (2019).
Input and output of a BERT sequence pair classifier. Original image by Artetxe et al. (2019).
In a supervised setting, which involves previously seen targets and languages, we find that BERT can clearly surpass a simple majority-class baseline:
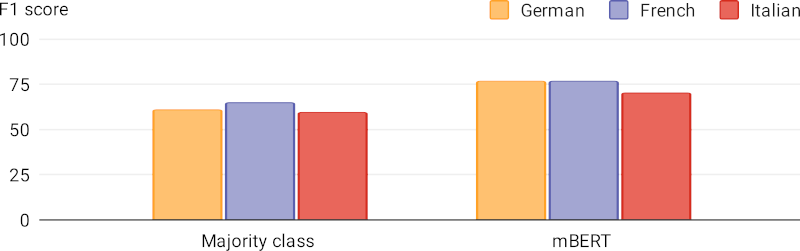
In the cross-lingual setting, the zero-shot performance in Italian is much better than the baseline. But the performance is higher in German and French, because the model has been trained on samples in those languages.
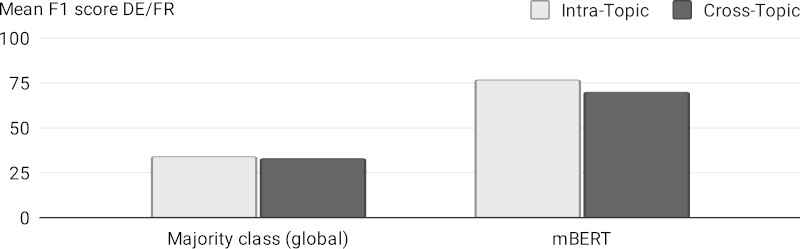
Finally, the model can also generalize to held-out topics. If the model is asked to detect the stance of a text towards a previously unseen target, it performs better than a global majority-class baseline:
Bringing it All Together
Given the x-Stance dataset for stance detection, a multilingual BERT model has some capability to perform zero-shot transfer to unseen languages and to unseen targets. However, there is a gap in performance between the supervised settings and the zero-shot settings that future work could address. For example, even better representations or a more sophisticated classification architecture could be used.
Learn More about x-Stance
-
Our GitHub repository contains the full dataset as well as the evaluation script and the code for our baselines.
-
The x-Stance paper has been presented at the 5th SwissText & 16th KONVENS Conference 2020. In the paper you will find more details, and also references to related work, which have mostly been omitted in this blog post.
-
x-Stance is also part of the datasets library from Huggingface. Use the live viewer to have an interactive look at the dataset.
The work presented in this post is joint work with my PhD supervisor Rico Sennrich. It was funded by the Swiss National Science Foundation (project MUTAMUR; no. 176727).
References
Mikel Artetxe, Sebastian Ruder, and Dani Yogatama. On the cross-lingual transferability of monolingual representations. arXiv preprint arXiv:1910.11856, 2019. ↩
Saif Mohammad, Svetlana Kiritchenko, Parinaz Sobhani, Xiaodan Zhu, and Colin Cherry. SemEval-2016 task 6: detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), 31–41. San Diego, California, June 2016. Association for Computational Linguistics. URL: https://www.aclweb.org/anthology/S16-1003, doi:10.18653/v1/S16-1003. ↩
Mariona Taulé, M Antònia Martí, Francisco Rangel, Paolo Rosso, Cristina Bosco, and Viviana Patti. Overview of the task on stance and gender detection in tweets on catalan independence at ibereval 2017. In 2nd Workshop on Evaluation of Human Language Technologies for Iberian Languages, IberEval 2017, volume 1881, 157–177. 2017. URL: http://ceur-ws.org/Vol-1881/Overview5.pdf. ↩
Mariona Taulé, Francisco Rangel, M Antònia Martí, and Paolo Rosso. Overview of the task on multimodal stance detection in tweets on catalan #1oct referendum. In 3rd Workshop on Evaluation of Human Language Technologies for Iberian Languages, IberEval 2018, volume 2150, 149–166. 2018. URL: http://ceur-ws.org/Vol-2150/overview-Multistance18.pdf. ↩