
Mit der zunehmenden Nutzung von Sprachmodellen im Alltag wird auch die Frage relevant, ob diese eine politische Schlagseite haben. Die Tamedia-Zeitungen haben Anfang der Woche über eine Studie berichtet, die genau das untersucht hat. In dieser Studie wurde ein englischsprachiger Fragebogen (Political Compass) verwendet, um Sprachmodelle auf ihre politische Ausrichtung zu testen.
Ein Ergebnis war, dass ChatGPT tendenziell links der Mitte zu verorten ist. Allerdings ist der verwendete Fragebogen – wie vieles in der Politik – nicht ganz unumstritten. In der Schweiz gibt es mit Smartvote seit 20 Jahren einen Fragebogen, der sich bewährt hat, und heute wurde eine neue Version für die eidgenössischen Wahlen im Oktober 2023 aufgeschaltet. Jetzt bietet es sich an, ChatGPT auch diesen Fragebogen ausfüllen zu lassen.
Der neue Fragebogen vom Smartvote enthält 75 Fragen, von Umwelt und Energie über gesellschaftliche Fragen bis zum Bundeshaushalt. Smartvote erstellt anhand des Fragebogens eine Grafik mit grossem Wiedererkennungswert, genannt Smartspider. Eine weitere Besonderheit von Smartvote ist die Mehrsprachigkeit. Diese hat mich vor drei Jahren schon zu einem anderen computerlinguistischen Experiment inspiriert.
Um ChatGPT den Smartvote-Fragebogen beantworten zu lassen, muss man kein Experte sein. Die Idee ist auch nicht komplett neu. In diesem Blogpost möchte ich die Idee aber etwas genauer anschauen:
- Ich vergleiche ChatGPT mit dem aktuell grössten Open-Source-Sprachmodell (LLaMA 2), welches weniger einfach zugänglich ist als ChatGPT.
- Ich stelle die Fragen in allen vier Landessprachen, plus Englisch. Interessanterweise hat die Sprache einen Einfluss auf das Resultat – was verschiedene Gründe haben könnte.
- Ich erkläre, warum mehrfaches Generieren von Antworten oder eine Analyse der Wortwahrscheinlichkeiten wichtige Methoden sind, um die Tendenzen eines Sprachmodells zu erfassen.
ChatGPT vs. LLaMA 2
ChatGPT ist ein kommerzielles Sprachmodell von OpenAI, das von registrierten Nutzer*innen kostenlos benutzt werden kann. Leider sind die technischen Details von ChatGPT nicht öffentlich zugänglich. Darum ist es nützlich, auch Open-Source-Modelle zu haben, die man genauer unter die Lupe nehmen kann.
Ein solches Open-Source-Modell ist LLaMa 2 von Meta. Ich lege den Smartvote-Fragebogen sowohl ChatGPT als auch LLaMa 2 vor, und zwar der grössten Version von LLaMa mit 70 Milliarden Parametern, welche für Chat-Applikationen optimiert wurde.
Ein erster Vergleich zeigt, dass beide Modelle eine ähnliche Smartspider-Grafik erhalten:
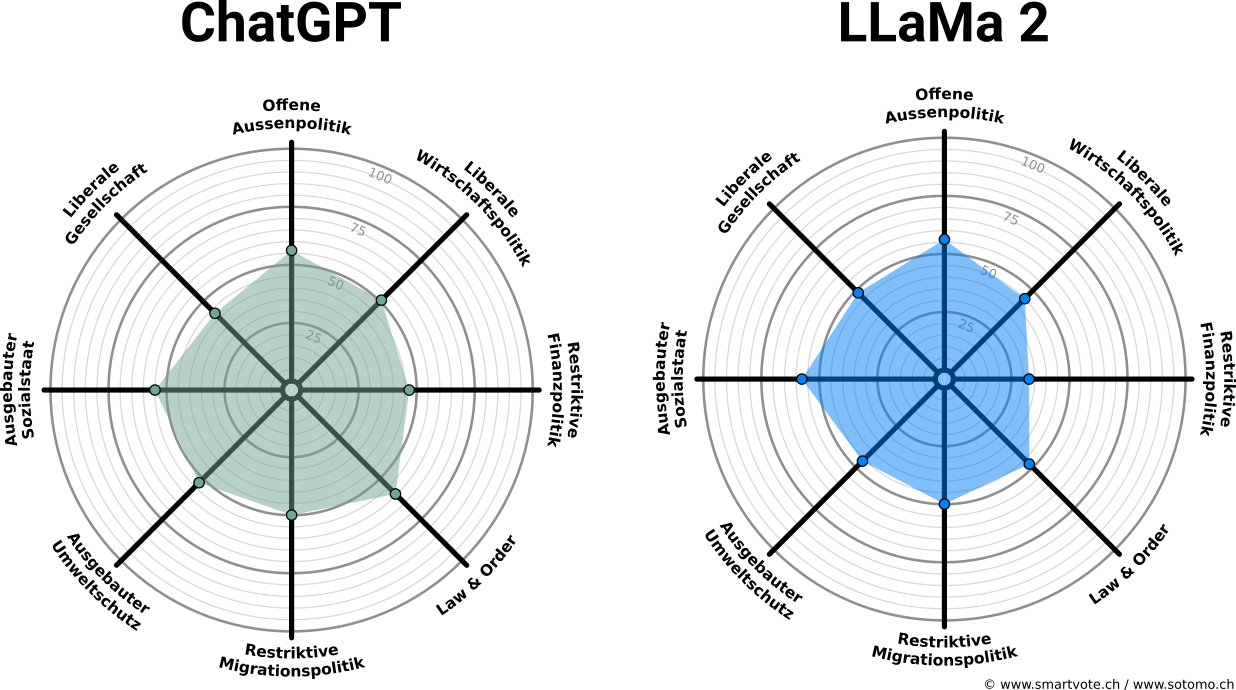
Beide Spiders sind stark eingemittet. Das muss aber nicht heissen, dass die Modelle in ihren Antworten übereinstimmen:
Nur auf 38 von 75 Fragen geben sie die gleiche Antwort.
Vielmehr neigen die Modelle dazu, gemässigte Antworten zu geben ("eher ja", "eher nein"):
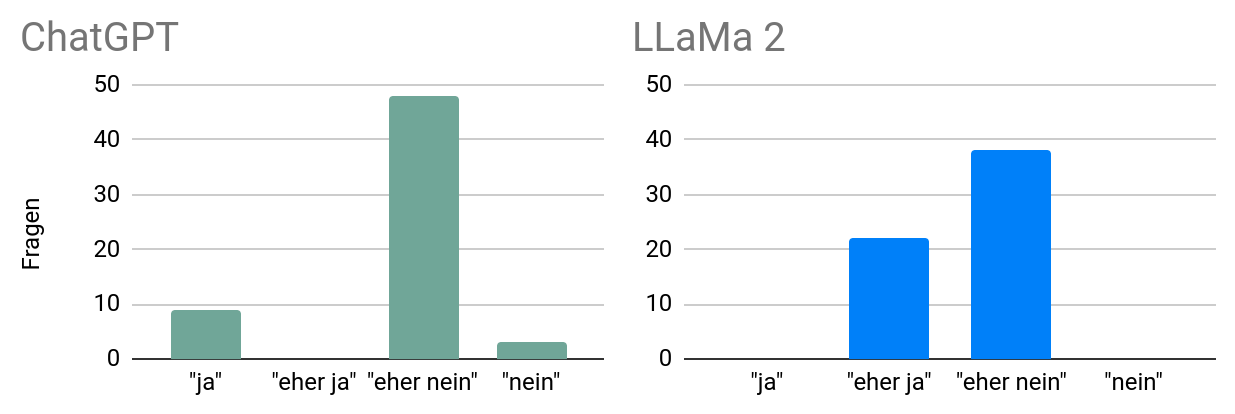
Einen ausgeprägten Smartspider erhält aber nur, wer hin und wieder auch entschiedene Antworten gibt ("ja", "nein").
Spielt die Sprache eine Rolle?
Bis jetzt habe ich die Fragen nur auf Deutsch gestellt. Sehen die Smartspiders auch gleich aus, wenn die Fragen auf Französisch, Italienisch oder Rumantsch gestellt werden, oder auf Englisch? Für diese Sprachen stellt Smartvote eine Übersetzung der Fragen und Antwortoptionen zur Verfügung. Wenn man diese dem Sprachmodell vorlegt, zeigt sich, dass zum Teil recht verschiedene Smartspiders herauskommen:
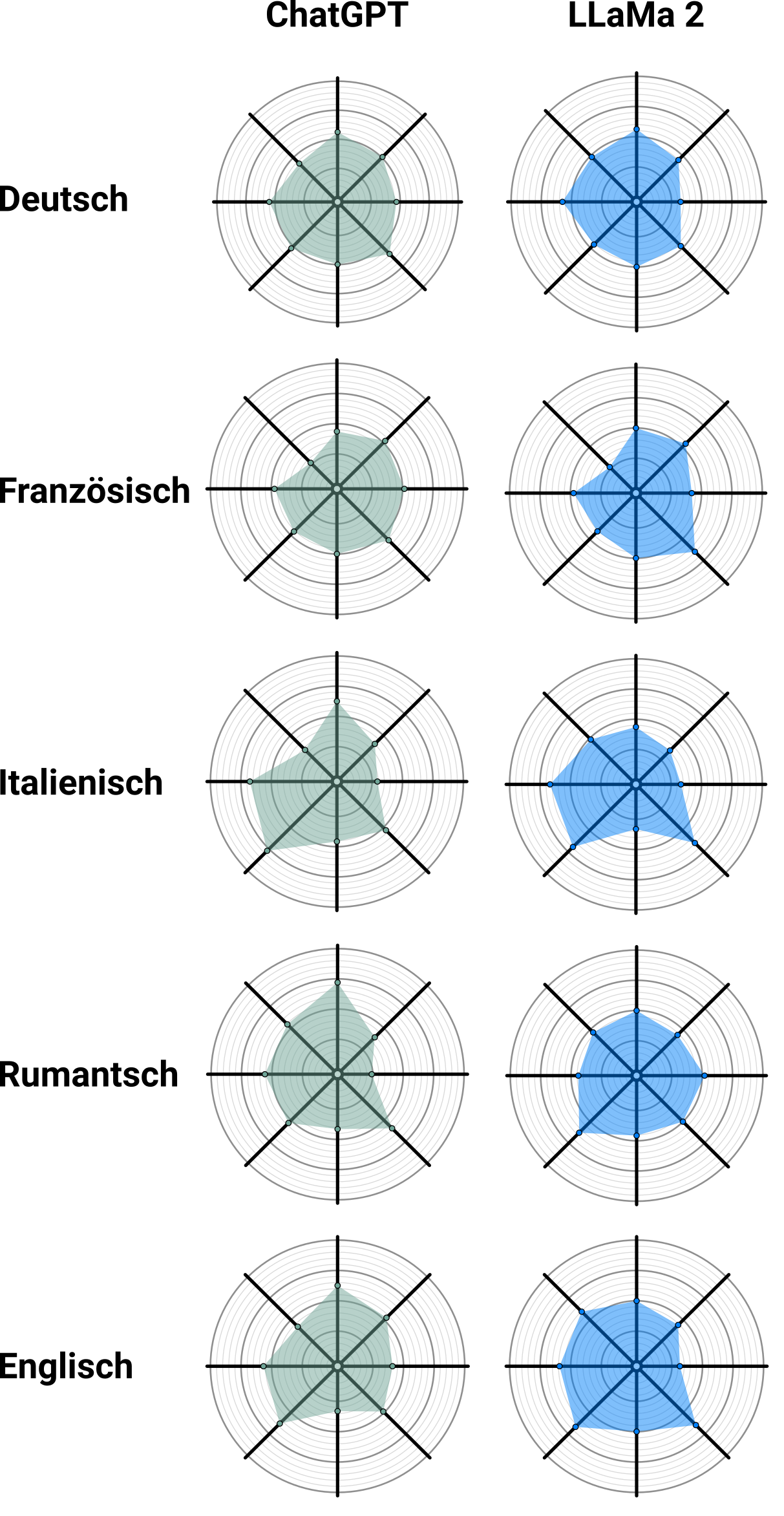
Der erste Gedanke ist sicher, dass die Sprache und damit auch der Kulturraum einen Einfluss auf die Antworten des Sprachmodells hat. Oft spricht man in der Schweiz vom Rösti- und Polentagraben, der die verschiedenen Sprachregionen auch politisch trennt. Konkret könnte ich mir vorstellen, dass italienischsprachige Texte, auf denen ChatGPT trainiert wurde, im Durchschnitt leicht andere Meinungen propagieren als etwa Texte in deutscher Sprache.
Allerdings kann ich mir auch einen profaneren Grund vorstellen: Zufall. Vielleicht werden die Sprachmodelle von Oberflächlichkeiten beeinflusst – zum Beispiel von der Länge der Fragen, der Reihenfolge der Antwortoptionen und von der Wortwahl. Eine solche fehlende Robustheit ist in der Computerlinguistik oft zu beobachten.
Um das zu überprüfen, könnte man die Fragen umformulieren und schauen, ob das Modell dann eine andere Meinung ausgibt. Das wäre ein interessantes Experiment für die Zukunft. Würde sich ein Mangel an Robustheit bestätigen, dann wäre es in meinen Augen nicht mehr korrekt, von der "Meinung" oder von der "politischen Ausrichtung" eines Sprachmodells zu sprechen.
Stattdessen wäre der Smartspider von ChatGPT einfach ein Zufallsprodukt, das Ergebnis eines Prozesses, der gar nichts mit Politik zu tun hat. Trotzdem können Sprachmodelle eine Bias oder Voreingenommenheit aufweisen. Nur könnte man diese nicht anhand eines politischen Fragebogens quantifizieren.
Zur Methodik
Grundsätzlich kann man eine Frage einfach ins Chatfenster eingeben und versuchen, die Antwort in das Schema "ja", "eher ja", "eher nein", "nein" einzuordnen:

Dieser Ansatz hat aber zwei Nachteile:
- Oft verweigert das Sprachmodell eine entschiedene Antwort – schliesslich wurde es vom Hersteller dazu trainiert, bei heiklen Fragen auf der sicheren Seite zu bleiben.
- Die Antwort, die wir bekommen, ist für das Modell gar nicht unbedingt die allerwahrscheinlichste Antwort. Stattdessen wird die Antwort durch eine Stichprobe erzeugt, bei der auch ein bisschen Zufall im Spiel ist. Wenn man die Frage noch einmal stellt, bekommt man vielleicht die gegenteilige Antwort.
Die Methode, die ich für diesen Blogpost gewählt habe, ist daher etwas komplizierter. Ich weise das Sprachmodell an, entweder mit A, B, C oder D zu antworten. Ich teile dem Modell mit, dass A "ja" heisst, B "eher ja" heisst, etc. Dann vergleiche ich, welche Wahrscheinlichkeiten das Modell den Wörtern zuweist: Ist "A", "B", "C" oder "D" am wahrscheinlichsten als nächstes Wort? Das kann man nicht via das Chatfenster machen, sondern man braucht Programmcode wie zum Beispiel das Projekt LMQL von der ETH Zürich.

Man könnte es auch so formulieren, dass ich das Sprachmodell zwinge, eine der vorgegebenen Antworten zu generieren. Andere Antworten als A, B, C oder D sind nicht erlaubt (forced choice).
Im Fall von ChatGPT ist es noch nicht möglich, die Wahrscheinlichkeiten der einzelnen Wörter zu analysieren. Dafür ist die API von OpenAI im Moment nicht geeignet. Ein äquivalenter Ansatz ist es, eine Antwort viele Male neu generieren zu lassen. Wenn man dann zählt, wie oft "A", "B", "C" und "D" herauskommt, kann man die zugrundeliegenden Wahrscheinlichkeiten abschätzen. Das habe ich für ChatGPT so gemacht.
FAQ
Wie lauten die Fragen genau?
Der Fragebogen ist auf der Website von Smartvote verfügbar.
Wie wird der Smartspider berechnet?
Der Smartspider wurde von Smartvote so definiert, dass ein Teil der Fragen einer oder mehreren Achsen zugeordnet wird. Die genaue Zuteilung ist in einem PDF dokumentiert.