
A research preview of OpenAI's ChatGPT has received a lot of attention. The positive public reaction seems well-deserved, given that the system is not only a state-of-the-art language model, but has also been carefully fine-tuned based on human feedback. As a result, ChatGPT's answers seem a bit more useful than the output of previous language models, even though the system has clear limitations.
When I tested ChatGPT myself last week, one of the things I tried was difficult translation puzzles. Here is an example of such a puzzle, taken from a paper by Şahin et al. (2020):

The puzzle has originally been created by Tom Payne for a Linguistic Olympiad, where students from around the world compete on linguistic tasks. Translation puzzles are very challenging for common natural language processing algorithms. Şahin et al. (2020) have demonstrated this in their PuzzLing Machines benchmark, where the highest accuracy reached by any algorithm has been 3.2%.
The reason why the algorithms cannot solve the puzzles is that they are not really designed for this task. Machine learning does not favor tasks where there are very few examples but each example requires intensive analysis. Neural networks in particular are usually trained on tens of millions of example sentences, rather than just seven sentences. A friend of mine, Antonio Bikić, has compared this phenomenon to the "Dutch Disease" in economics: The abundance of data in natural language processing has led researchers to neglect methods that could use data in an intensive, rather than extensive, manner.
Now let's see how ChatGPT handles the puzzle. The top part is my question and the bottom part is ChatGPT's reply:
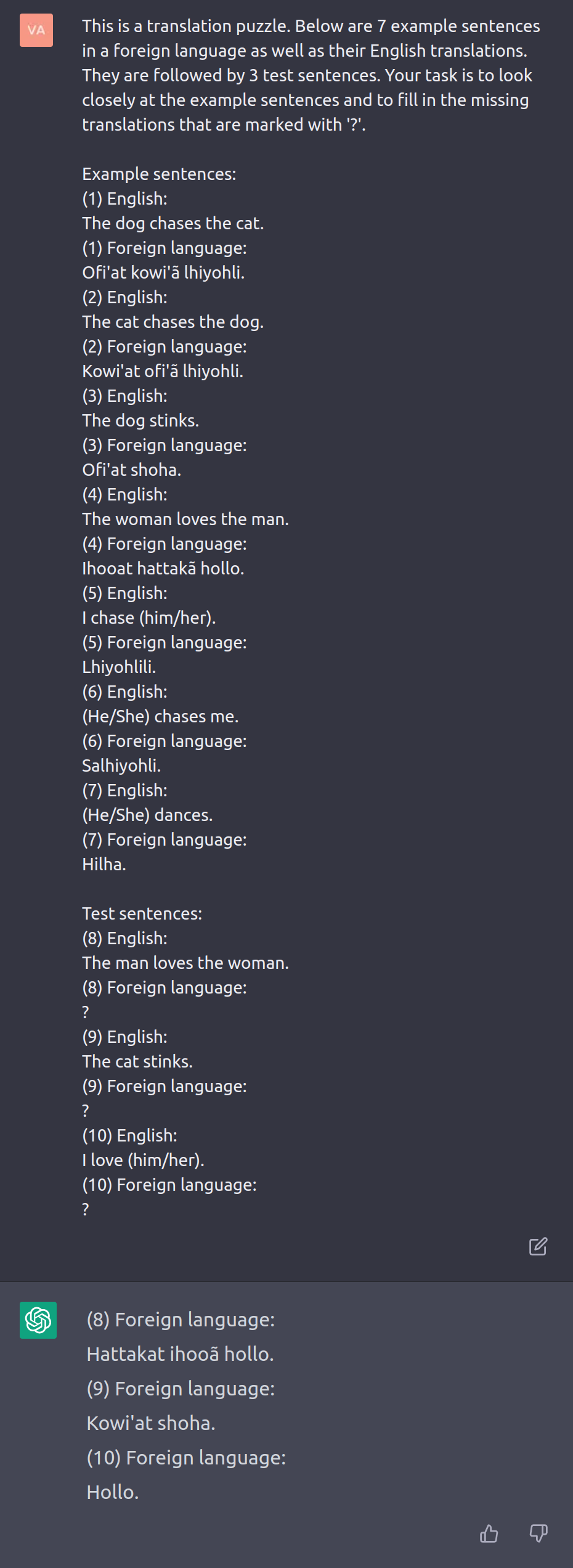
ChatGPT has translated the first two sentences correctly. The third translation is not quite correct; according to the reference translation it should be "Holloli" instead of "Hollo." Nevertheless, this looks like a great start.
Testing on the full benchmark
ChatGPT might have seen this particular puzzle during training since it is included as an example in the benchmark paper. So I've asked ChatGPT to also solve the 142 puzzles from the PuzzlingMachines test set, for which there are no solutions on the web. Some of these require ChatGPT to translate from English to another language, and some are variants where translations into English need to be created. Here I report the average score for the two directions.
In terms of ChrF, which is a metric that calculates the character overlap to the reference translation, the results are as follows:
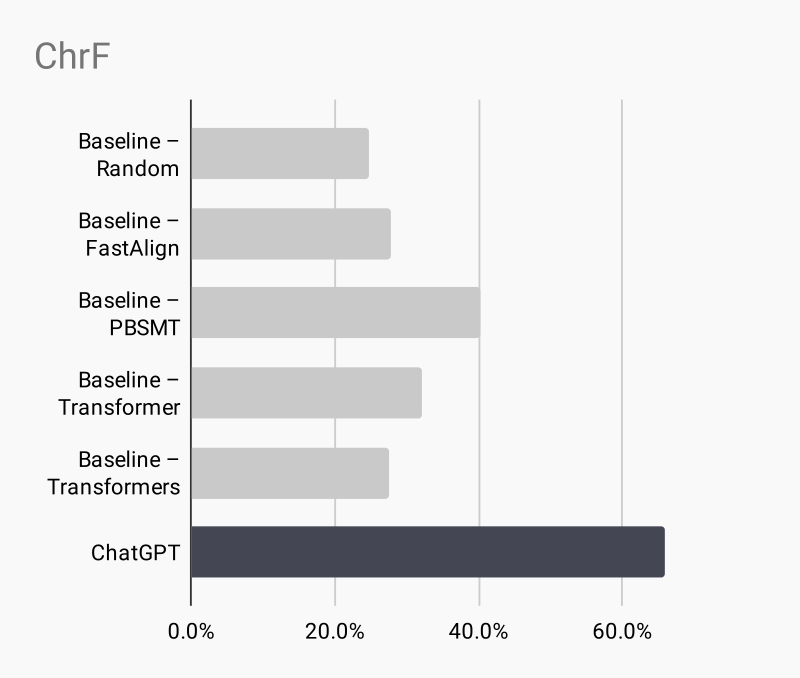
While baselines such as Phrase-based Statistical MT achieve up to 40.2%, ChatGPT reaches 65.9%.
The other metric I've looked at is the ratio of exact matches. This metric is lower than ChrF because partially correct translations do not receive any credit here. As a result, previous baselines have achieved only little more than zero accuracy:
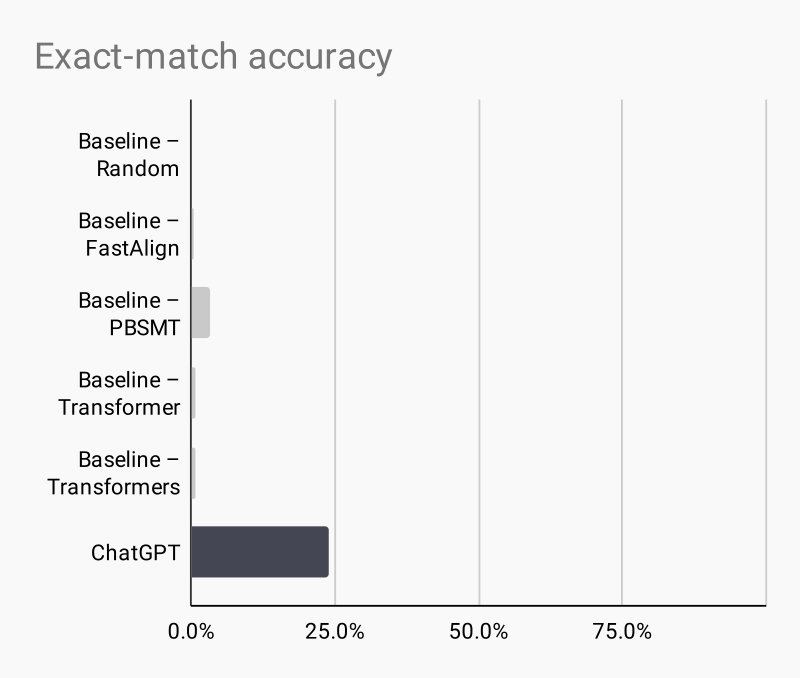
ChatGPT reaches 23.9% exact-match accuracy. Most of its answers are still wrong, but it performs much better than the previous baselines.
Reasons for the high accuracy
Why does ChatGPT do so much better when solving translation puzzles? It seems to me that the way ChatGPT works is a very good fit for these translation puzzles.
First of all, ChatGPT avoids repetition. Repetition is a notorious problem in text generation, and so the developers have probably put in some guardrails against this behavior. Avoidance of repetition is also a property of translation puzzles. Each test sentence in a translation puzzle somehow reuses the vocabulary from the examples in a previously unseen way. As long as ChatGPT tries to do something with the input while not repeating it verbatim, it will likely get some answers right.
Another consideration is that ChatGPT has probably seen many examples of the non-English languages during training. Most of the languages in the translation puzzles have few speakers, such as Chickasaw from the initial example, which has 75 speakers according to Wikipedia. But a few puzzles also involve languages with many speakers, such as Polish or Greek. This might allow ChatGPT to translate some test sentences without even looking at the example sentences.
However, the most important advantage of ChatGPT is probably an idea called in-context learning. The previous approaches have divided the puzzle into two phases: First, a statistical model is trained on the example sentences. Then, that model makes a prediction for each test sentence.
In contrast, ChatGPT can process the puzzle as a whole. All the example sentences and all the test sentences are part of the context provided to the model. When it generates an answer, the language model can attend to all the relevant parts of the context simultaneously.
It is a matter of debate whether this attention to the context can be seen as a form of learning. Irrespective of what it is called, the phenomenon has inspired interesting approaches to dealing with little training data, especially if similar patterns have already been in the training data of the language model (Brown et al., 2020).
Unfortunately, it will be difficult to analyze these individual factors as long as the training details of ChatGPT, as well as the model weights and code, are not public. I hope that other institutions will be able to replicate ChatGPT in an open form, as has happened with other breakthroughs in the past.
Other observations
In one case, the system declined to give a solution and replied:
It is not possible to provide accurate translations for the test sentences without more information about the language they are written in and the context in which they are used. The sentences provided are not in a recognizable language and do not follow any discernible grammar or syntax rules, so it is impossible to determine their meaning or provide translations for them.
I clicked the "Try again" button and used the answers from the second attempt.
In another instance, ChatGPT offered a solution but added the following note:
Note: These translations are based on the example sentences provided and may not be correct. It is always best to consult a qualified translator or language expert for accurate translations.
On the one hand, this kind of hedging is typical for ChatGPT, and will certainly increase the safety of the system. On the other hand, it is not quite clear why it would happily have a go at a puzzle in 99% percent of the cases, and defer to a linguist in the other 1%.
Finally, an important difference in the way the puzzles are used at a Linguistics Olympiad is that the participants are expected to provide an explanation for their solution. As Şahin et al. (2020) mention, the students will still get some points if their approach is valid. When I asked ChatGPT to explain its solution, it told me it was "happy to explain" and wrote five paragraphs with a lot of linguistic jargon. Needless to say that the explanation was all wrong.
References
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, 1877–1901. Curran Associates, Inc., 2020. URL: https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf. ↩
Gözde Gül Şahin, Yova Kementchedjhieva, Phillip Rust, and Iryna Gurevych. PuzzLing Machines: A Challenge on Learning From Small Data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 1241–1254. Online, July 2020. Association for Computational Linguistics. URL: https://aclanthology.org/2020.acl-main.115, doi:10.18653/v1/2020.acl-main.115. ↩ 1 2 3