
It was a nice coincidence that the Stable Diffusion model was released right before my vacation. While DALL·E 2 had popularized image generation with diffusion before, few people have access to it. In contrast, Stable Diffusion is open source, and hundreds of developers and artists all over the world have started to experiment with it and have been sharing their creations online. Since I now had a week of free time at hand, I decided to explore the model on my own. In this blogpost, I document the three mini-inventions that I came up with.
Hypermosaics
photo of a turtle all the way down #stablediffusion pic.twitter.com/JlHyHTscxq
— Jannis Vamvas (@j_vamvas) September 11, 2022
I think many people have heard of photomosaics, which go back to the nineties. People who have tried creating a photomosaic will also know how difficult it is. The goal of a photomosaic is to compose a primary image out of a large number of component images. Because all these images are pre-defined – e.g., they are photos made by human photographers – the process is computationally complex and usually requires a few tricks, such as manipulating the color of the component images.
In contrast, creating a photomosaic using images generated by Stable Diffusion is straightforward.
Let's start with creating the primary image. In this example, I am using the prompt “photo of a turtle” throughout.

Given a primary image, we can then generate the component images top-down. Let's divide the image into tiles (I am using a 64×64 grid).

We can then upsample each tile to 512×512px and use it as an input for generating another photo of a turtle. As you can see in the example above, this process (called img2img) preserves the color gradient in the original tile, which is important for rendering the details of the primary turtle.
As a result, a mosaic generated with Stable Diffusion can be much more detailed than a traditional photomosaic.

You could argue that a mosaic made out of generated images is somewhat pointless, and I agree. The reason image generators are interesting is that it is now possible to create what I call a hypermosaic, which would be very difficult without an image generator.
A hypermosaic is an image that is composed of other images, which in turn are composed of other images, and so forth – a hypermosaic has infinite resolution! To stick to the turtle example: A hypermosaic is “photo of a turtle” all the way down.
With some manual stitching I was able to create a proof of concept within hours based purely on generated images of turtles. The looped video in the tweet above is the outcome (here is a 10MB GIF). Let me know in the comments what you think. My personal opinion: It could make a nice screensaver!
Prompt Ensembling
Not sure if people have already been doing that, but I find it amazingly easy to ensemble #stablediffusion conditioned on two different prompts.
— Jannis Vamvas (@j_vamvas) September 13, 2022
Can you guess the two prompts behind these photos? pic.twitter.com/pkyuwzRPce
When people explore the capabilities of image generators, they often try to combine concepts that are rarely seen together (chair+avocado or astronaut+horse). However, Stable Diffusion cannot combine all concepts out of the box. For example, this is what you get for the prompt “photo of a giraffe that looks like a frog”:

Not too impressive, right? You get something similar if you put “photo of a mixture of giraffe and frog”:

Thus, mixing giraffes and frogs calls for a more hands-on approach. A concept that is well-known in machine translation is to combine multiple models at inference time (ensembling). When working with a single model, one can also combine multiple instances of the same model that are each provided with a different input. Here this would mean to combine an instance of the image generator that is conditioned on ”photo of a giraffe“ with one that is conditioned on ”photo of a frog“.
This approach can also be understood as an interpolation of two conditional models, but to avoid confusion with prompt interpolation I will use the term ensembling.
Let's look at a nice schema of Stable Diffusion created by Hugging Face:
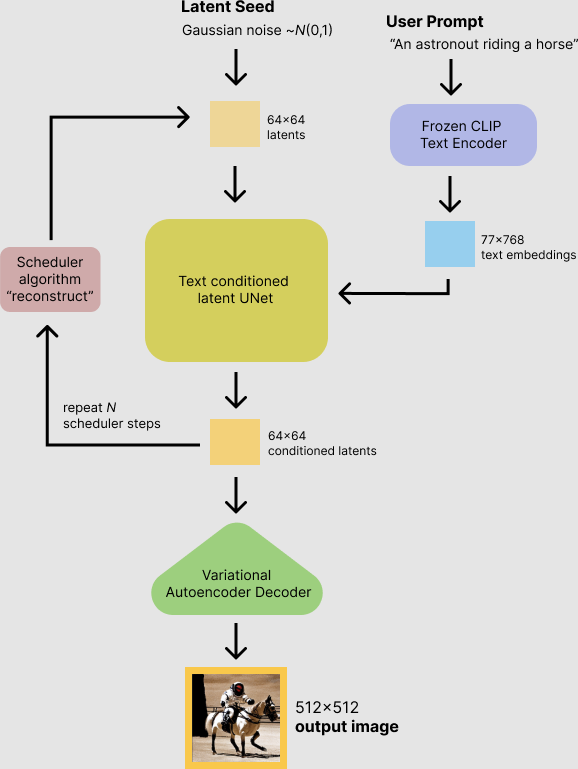
{kind=link}
According to the schema, conditioned latents are iteratively created by conditioning a UNet on the embedded user prompt and a previous latent. A straightforward way to ensemble two prompts would then be to average the two conditioned latents at each step before feeding them back into the UNets:
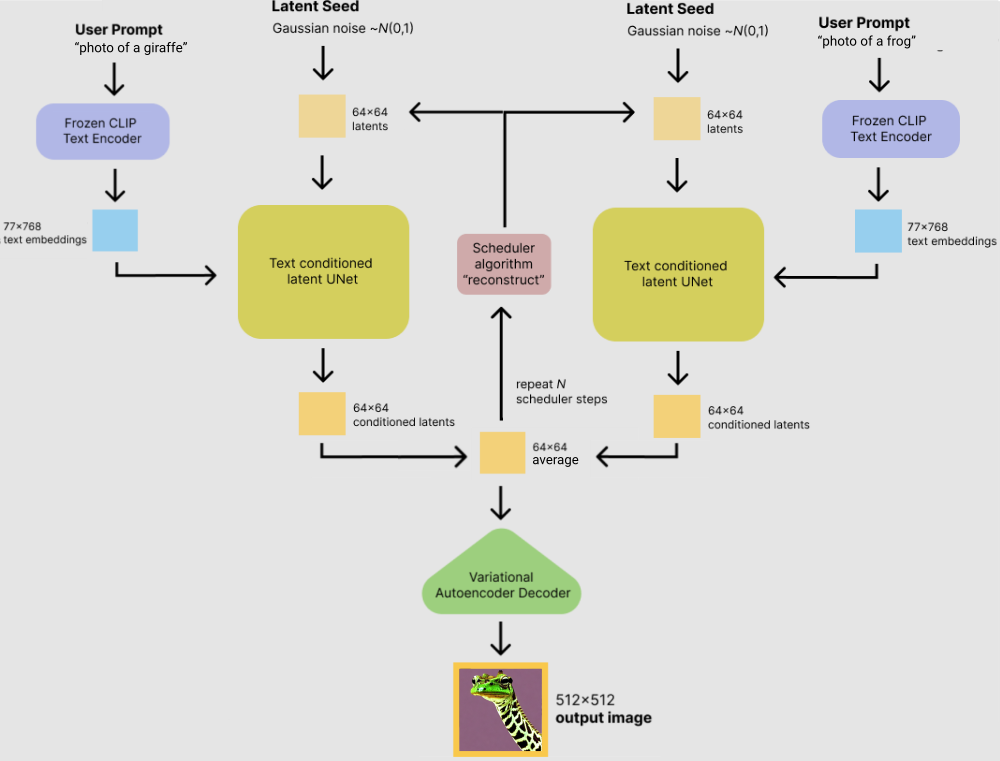
Here is an implementation of this idea that I made using the Hugging Face diffusers library. I just needed to add 18 lines.
If we now ensemble the prompts “photo of a giraffe” and “photo of a frog” (with default settings and for 80 steps), this is what we get:

The ensembling works in the sense that both prompts are represented in the images. However, the model has a hard time combining them in a meaningful or creative way. In the upper right image, we just see a frog next to a tiny giraffe (which could be seen as a local minimum of what we want to achieve). So it seems we need to help the model further to converge to a unified object.
We can do this by ensembling the prompts “photo of a giraffe that looks like a frog” and “photo of a frog that looks like a giraffe” (which we had used individually in the first example). Now finally we are receiving acceptable images, some of which could even be considered useful and interesting:

Picture Frame Inpainting
To conclude this post, I would like to share my attempt to put Stable Diffusion into real-world use.
An idea that has achieved quite a lot of attention is inpainting, i.e., completing a region inside the image by using the remainder of the image as context. For example, there is a popular web UI for Stable Diffusion that supports inpainting, and there are plugins for various graphics editors.
I decided to try out inpainting by inpainting the inside of actual picture frames:
For people looking to experiment with #stablediffusion, I can truly recommend the Krita plugin by @NicolayMausz
— Jannis Vamvas (@j_vamvas) September 7, 2022
Below: Inpainting picture frames of various styles. Prompt: painting of a dog pic.twitter.com/9OFQ48hzrN
My hope was that the image generator would ”attend“ to the surroundings of the picture frame when inpainting the image into the frame. It is difficult to estimate to what degree this actually happens, and my experiments were not always successful. However, in the (cherry-picked) images above, there are some indications that the image generator considers the context sometimes. For example, on the upper right the dog's colors match the photo from the IKEA product catalog (original image). And on the lower left, the dog's hair might reflect the wooden floor of the apartment.
As a final digression I decided to make a step into the physical world and to let Stable Diffusion inpaint an image into my own apartment. There was a picture frame that had long been empty:

Using the prompt “drawing of an animal”, I then inpainted the frame virtually.

After a few tries I got an acceptable result. I was not completely satisfied with the colors, because many of the inpaintings were gray or had a very faint green. I suspected this was caused by the white bookshelf and the wall, but was not able to get to the root of this phenomenon.
In order to have an actual art print, I had to upscale the inpainted image.
I scaled and padded the image to 512×512 and used the img2img function of Stable Diffusion to create a full-resolution image. For that I used the prompt “impressionist painting of a small deer hiding inside vegetation, high-resolution art print”.

In a second step, I upscaled the image with ESRGAN to get to about 240 DPI. The print is now standing on my bookshelf and, I hope, will decorate the apartment for many years to come.
