
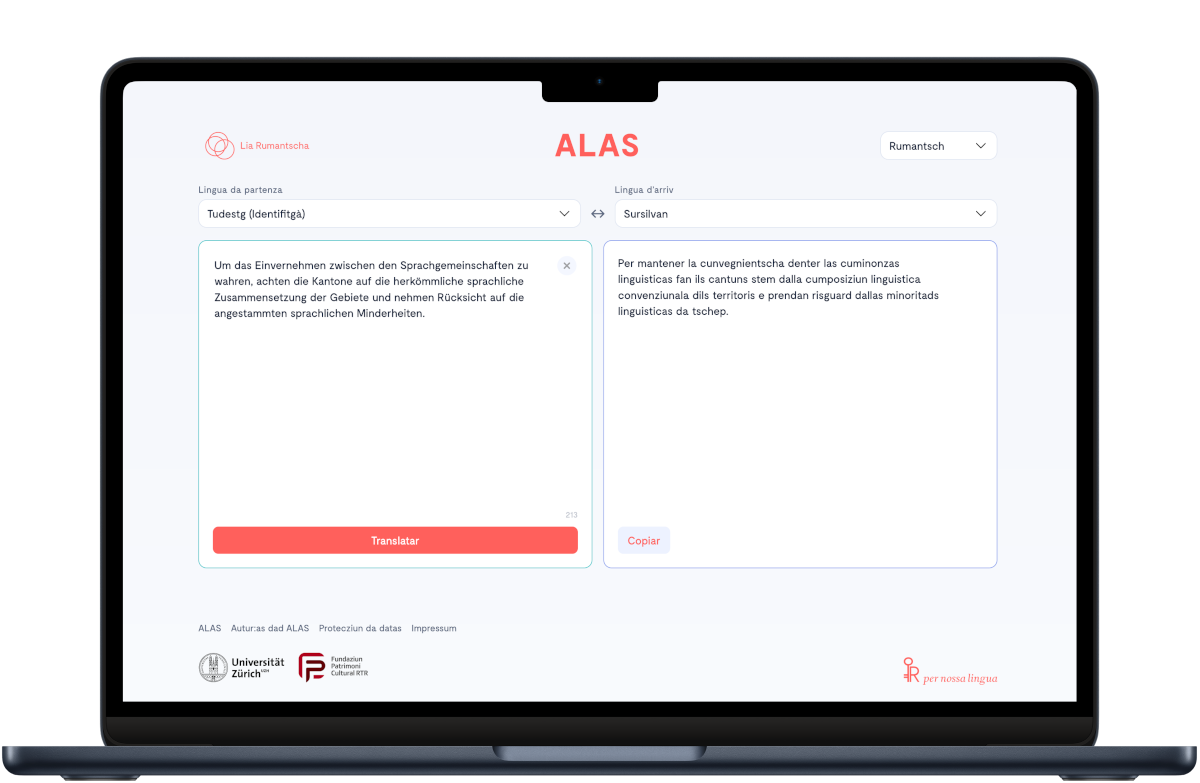
In collaboration with Lia Rumantscha, our team has developed «Alas», a new machine translation tool for the Romansh language. It generates automatic translations from German into all five Romansh idioms (Sursilvan, Sutsilvan, Surmiran, Puter, and Vallader) as well as a standard written language, Rumantsch Grischun. Translation from Romansh into German is also supported.
You can try the translation program for free at alas.liarumantscha.ch.
... or you can watch the news report from Swiss national television (in Romansh):
The underlying technology is a fine-tuned version of the NLLB translation model (Costajussà et al., 2024). The model is openly accessible on the Hugging Face Hub: ZurichNLP/romansh-nllb-1.3b-ct2
The most significant effort went into data collection. This involved:
- Creating human-translated test sets.
- Curating and pre-processing parallel and monolingual Romansh data from various sources.
- Performing a human evaluation with native speakers of all varieties.
All of this was done for six different language varieties with varying resource levels. To turn the monolingual data into MT training data, we used back-translation with Gemini, which we document in our paper «Translation Asymmetry in LLMs as a Data Augmentation Factor: A Case Study for 6 Romansh Language Varieties».
Working on this applied topic has been rewarding. It addresses a real need within the community, and closing the technological gap required a combination of frontier AI and human expertise.
I also found that the topic has been a good fit for collaboration with our Bachelor and Master students in Computational Linguistics at the University of Zurich, be it through a thesis or programming project, or as research assistants in our group. One highlight was the creation of a multi-parallel corpus based on 291 schoolbook volumes. This dataset is now openly available to the research community as well: ZurichNLP/mediomatix
More information on the research project is found on our UZH project page: https://www.cl.uzh.ch/en/research-groups/texttechnologies/research/machine-translation/romansh-idioms.html
References
Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Jeff Wang, and NLLB Team. Scaling neural machine translation to 200 languages. Nature, 630(8018):841–846, June 2024. URL: https://doi.org/10.1038/s41586-024-07335-x, doi:10.1038/s41586-024-07335-x. ↩