
Recently, OpenAI introduced a Predicted Outputs feature for its GPT-4o language model. This feature promises to speed up text generation when the output will largely match a known pattern (e.g., if the language model needs to repeat an input text with minor changes or additions):
Introducing Predicted Outputs—dramatically decrease latency for gpt-4o and gpt-4o-mini by providing a reference string. https://t.co/n6mqjQwQV1
— OpenAI Developers (@OpenAIDevs) November 4, 2024
Speed up:
- Updating a blog post in a doc
- Iterating on prior responses
- Rewriting code in an existing file, like @exponent_run here: pic.twitter.com/c9O3YtHH7N
What sparked my curiosity was the fact that OpenAI's documentation for this feature explains very little – too little, for my taste. They provide an example output, but the example is clearly wrong, and you can't reproduce it via the API.
So I set out to reverse-engineer the algorithm behind this feature, both to understand it myself and to be able to better explain it to my students.
The idea of providing a language model with a draft of the output is a well-known concept in NLP, and looks something like this:
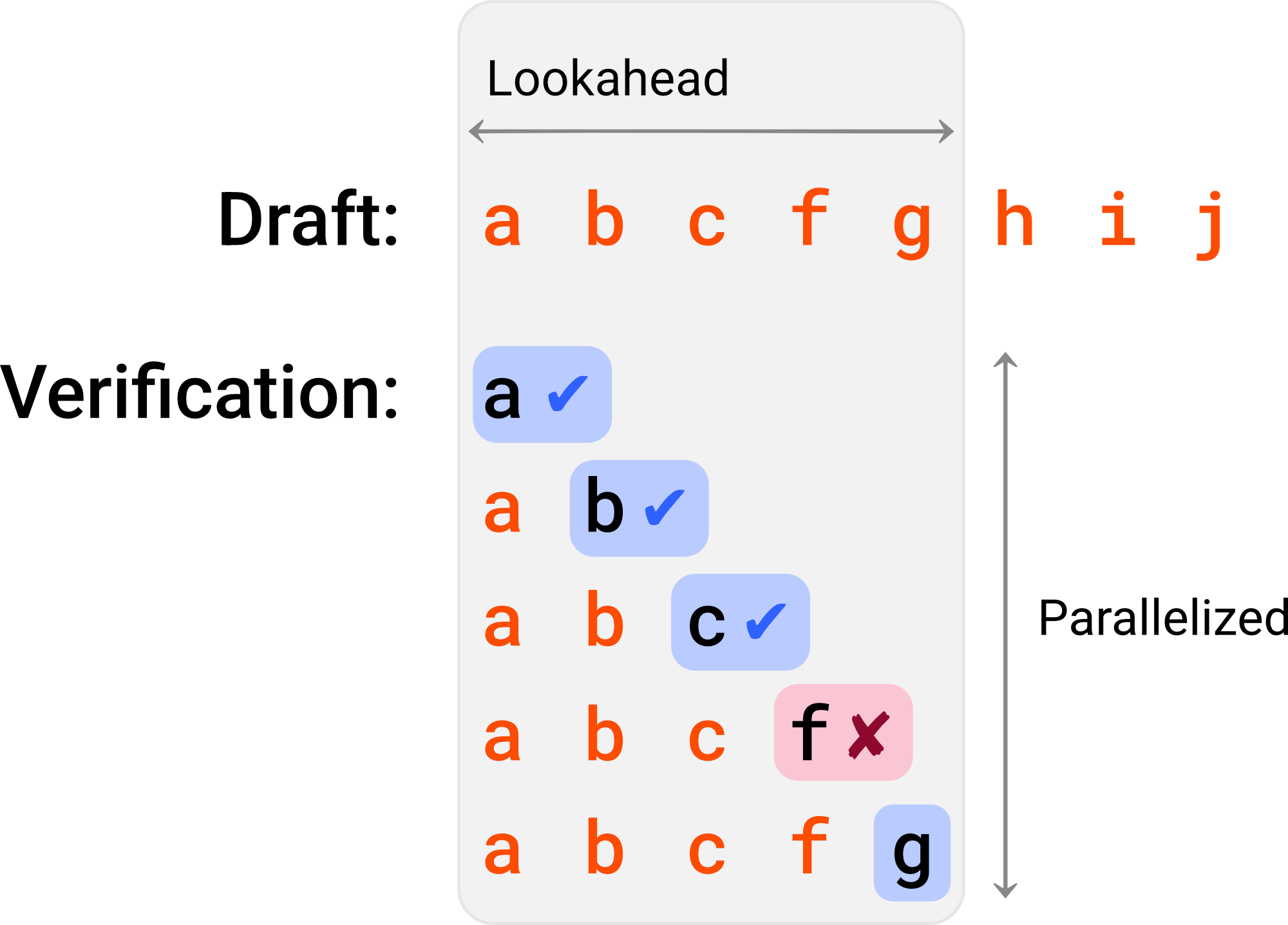
If the Predicted Outputs feature works this way, then it would be similar to Aggressive Decoding (Sun et al., 2021), or Prompt Lookup Decoding, which is implemented in HF Transformers and vLLM. There are also clear parallels to Speculative Decoding (Leviathan et al. (2023), Chen et al. (2023)), which uses a draft language model to predict the draft dynamically.
What makes OpenAI's algorithm different is that the draft is provided separate from the prompt, as an additional API parameter. Only one draft can be provided. Besides the generated response, the API response includes statistics of how many tokens in the draft were accepted and how many were rejected:

This doesn't make the response cheaper – in fact, rejected tokens are billed in addition to any accepted or additionally generated tokens – but it can speed up the response, since it is faster to verify a draft than to generate the tokens from scratch.
Key Concepts
To understand how the Predicted Outputs feature likely works, let's introduce some key concepts:
Lossless Acceleration
Algorithms like Speculative Decoding are lossless in the sense that they do not alter the generated response – the output remains exactly the same as it would be without the draft. The sole purpose of the draft is to accelerate text generation. If the LLM disagrees with any portion of the draft, the algorithm simply ignores that part. Similarly, the draft won't nudge the LLM toward a specific output. For instance, a draft cannot be used to make the LLM follow a particular output format.
Verification
A draft accelerates text generation because its tokens can be verified in parallel, whereas text generation from scratch cannot be parallelized and works in a sequential manner, token by token:
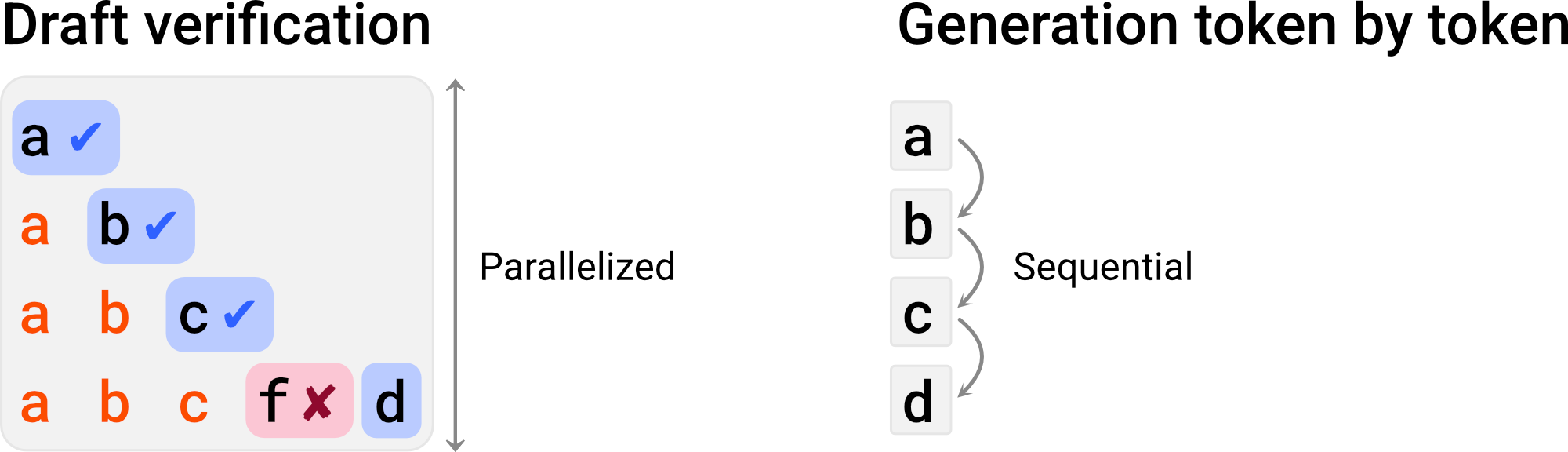
For simplicity, let's consider the case of greedy decoding, where the most likely token is selected at each step (as opposed to sampling, where tokens are selected with some randomness). In this context, verification means checking whether each draft token is indeed the most likely token according to the model, given the previous tokens. In the example above, this is true for the first three tokens in the draft, 'a', 'b' and 'c', but false for the fourth token, where the language model predicts 'd' as the most likely token.
Lookahead Parameter
In practice, verification is limited to a fixed number of draft tokens at a time. Since the draft is likely to be rejected at some point, any computation after the rejection point would be wasted. Defining a lookahead parameter helps reduce the expected number of rejected tokens.
OpenAI's Predicted Outputs – Reverse Engineering Report
To examine the Predicted Outputs feature, I relied on simple text generation tasks that involve enumerating the Latin alphabet. This has the advantage that a model like gpt-4o-mini is definitely able to solve the task, and so will always accept a correct draft and reject an incorrect draft. Furthermore, the gpt-4o/gpt-4o-mini tokenizer has a separate subword token for each letter in the alphabet, which makes it easy to calculate the expected number of tokens:

For basic tests, I simply asked GPT to list the letters in the alphabet:

When testing with longer sequences, I used a task where two letters need to be systematically paired:
Observation 1: Predicted Outputs is somewhat stochastic.
When repeating the same API call 25 times, four different responses are recorded:
This is with temperature 0. As expected, the model returns the same completion every time, but despite that, the number of accepted and rejected tokens varies.
One possible explanation is that OpenAI might batch my verification steps with verification steps from other users' requests, and the lookahead parameter could depend on how many tokens are available in the batch. However, it remains a puzzling observation, without a definitive explanation.
Code to reproduce this:
![]()
Observation 2: The lookahead parameter is K=16.
Next, let's analyze the size of the lookahead window. For this, we can simply provide a draft that is correct up to a point, and then continues with incorrect tokens. By varying the position where the draft begins to be incorrect ("bifurcation position"), we can track the behavior of the API:
While there are some minor variations in the graph, the trend is clear: The number of rejected tokens in this scenario never exceeds 16. This strongly indicates that OpenAI's lookahead parameter K is equal to 16: The algorithm verifies up to 16 tokens at a time, and therefore only rejects up to 16 tokens. After the first rejection, the algorithm likely generates the remainder of the sequence token by token.
Code to reproduce this:
![]()
Observation 3: Inserted, deleted, and replaced tokens are all treated the same way.
As one might expect, let's verify that the algorithm handles all types of discrepancies between the draft and the expected output in the same manner. Whether tokens are added, missing, or replaced in the draft, all these cases result in rejection of the affected tokens.
Correct draft
Accepted 5 – rejected 0.
Draft with added token: 'X' inserted between 'c' and 'd'
Accepted 3 – rejected 2.
Draft with missing token: 'd' deleted
Accepted 3 – rejected 2.
Draft with wrong token: 'd' replaced with 'X'
Accepted 3 – rejected 2.
Code to reproduce this:
![]()
Observation 4: The algorithm can recover after a rejection.
While an error in the draft will lead to rejected tokens, more tokens can still be accepted if the remainder of the draft is correct.
However, recovery doesn't happen immediately after the bifurcation position. Instead, there appears to be a specific number of tokens in the draft that need to be confirmed before verification resumes:
Correct draft
Accepted 55 – rejected 0.
Draft with added tokens
Accepted 21 – rejected 11.
Draft with missing tokens
Accepted 22 – rejected 11.
Draft with replaced tokens
Accepted 21 – rejected 11.
The examples above suggest that the number of tokens in the draft that need to be confirmed before the model can recover is approximately 32, which is twice the lookahead parameter.
I'm referring to this parameter as the "recovery threshold," but if it's already known by a different name in the literature, I'd be interested to know.
Code to reproduce this:
![]()
Bonus Observation: The "extra token" is not counted as accepted/rejected.
In the case of the Correct Draft above, 58 tokens were provided as a draft, but only 55 were accepted according to the API. The remaining three were neither accepted nor rejected, and I colored them in gray.
This is because during a verification step, we can not only verify K tokens, but we can also simultaneously predict the K+1st token, given the previous K tokens. This "extra token" can then be used for free, if and only if all previous K tokens were accepted.
OpenAI appears to bill the "extra token" as a token generated by the model, rather than a token from the draft. This is technically accurate, and since all tokens are charged at the same rate (as of writing this), it doesn't really matter that much.
Hypothesized Algorithm
Based on this analysis, we can now (more or less) formulate the algorithm that OpenAI appears to be using:

Evaluation
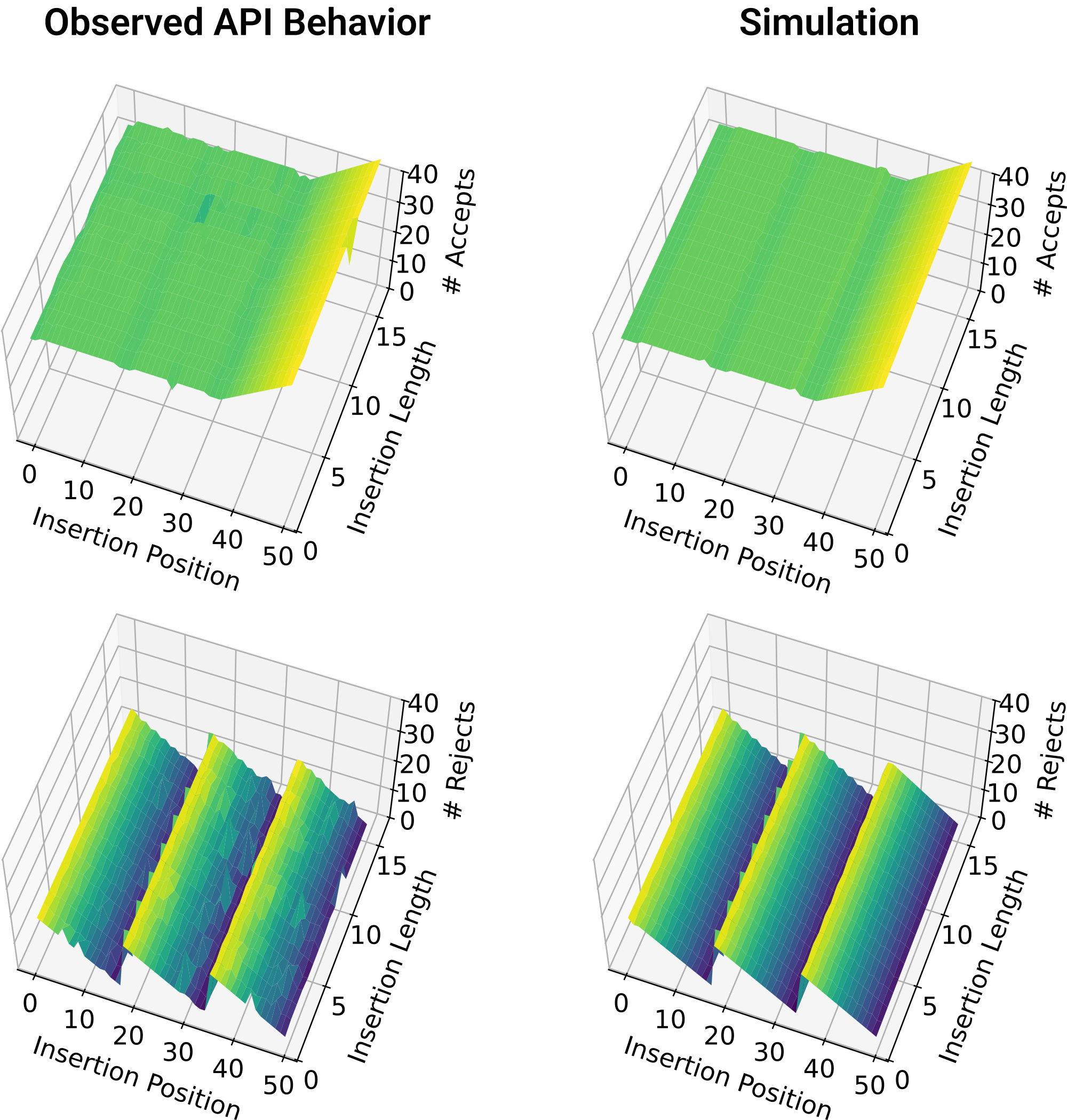
To check whether my implementation of the algorithm matches the API's behavior, I systematically tested scenarios where the language model needs to insert missing tokens into the draft. I varied both the position of the insertion and the number of tokens that needed to be inserted.
As established earlier, I set the lookahead parameter to 16 tokens and the recovery threshold to 32 tokens. Like before, I kept the temperature at zero.
When comparing the number of accepted and rejected tokens from my simulation with those returned by the OpenAI API, I found the results to be similar:
Code to reproduce this:
![]()
Conclusion
OpenAI's Predicted Outputs feature may lack documentation, but the algorithm behind it can be largely reverse-engineered by analyzing the number of accepted and rejected tokens for a given input.
A limitation of this analysis is that it only looks at greedy decoding. Generalizing the analysis to temperatures greater than zero would be interesting. Also, an open question is why the API responses are so stochastic. However, this is mostly an academic question, since the stochastic nature of the API is unlikely to be a deal-breaker for most practical applications.
Further Resources
References
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. 2023. URL: https://arxiv.org/abs/2302.01318, arXiv:2302.01318. ↩
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, 19274–19286. PMLR, 23–29 Jul 2023. URL: https://proceedings.mlr.press/v202/leviathan23a.html. ↩
Xin Sun, Tao Ge, Furu Wei, and Houfeng Wang. Instantaneous grammatical error correction with shallow aggressive decoding. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 5937–5947. Online, August 2021. Association for Computational Linguistics. URL: https://aclanthology.org/2021.acl-long.462/, doi:10.18653/v1/2021.acl-long.462. ↩